(12)日本人のルーツ Ⅲ 日本語の起源 OWLのひとりごと
![]()
日本人のルーツ(Ⅸ)日本語の成り立ち
2014.10.22
日本語の成り立ち 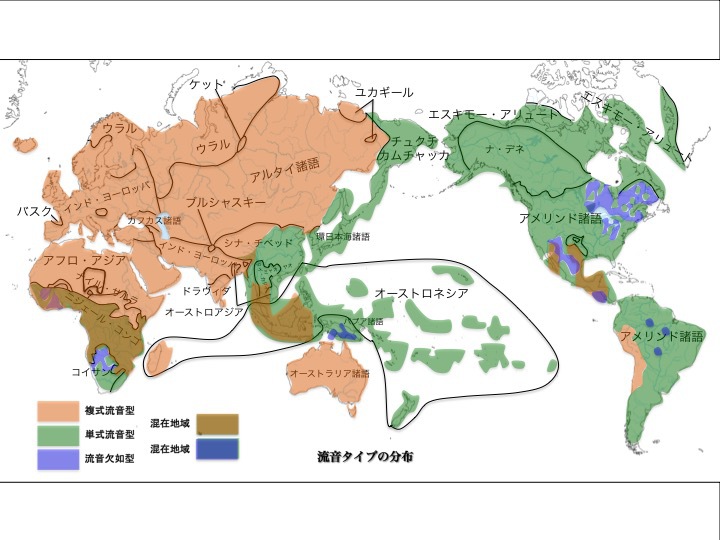
r(アール)l(エル)のどちらかしかない言語の分布
日本語の成り立ち
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
このページのまとめ
1)日本語が孤立言語であるという常識は覆された。
2)環太平洋言語圏という大きな集団に属している。
3)インド-ヨーロッパ語族よりも古く、たくさんの仲間がいる。
4)ユーラシア大陸の中では太平洋沿岸言語圏の北方群、環日本海諸語に属する。
5)Y染色体ハプログループ研究とあわせ、日本語は北方系ではなく、
6)南方系とくにオーストロアジア系に近い。
7)日本語のルーツはアジア大陸内部ではない。東南アジアだと言ってよい。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
Ⅰ)日本語が孤立言語と言われて久しい
日本語の系統関係は解明されていない。言語学からも音韻論からも「孤立言語」とされている。
世界の言語分布
ブルーで示してるのが孤立言語と呼ばれ、周囲の諸語とはグループを形成していない。
日本語を含む環日本海諸語(緑)も孤立言語の一つである。
より大きな図はこちら
アルタイ諸語に入るという説もある。上代日本語(大和言葉、奈良時代の日本語)では、語頭に流音(ラ行)が立たず、母音の組合わせに一定の制限がある「母音調和」を認める。これがアルタイ型の類型を持っているとされる所以だ。
しかし、アルタイ系と呼ばれる言語は、互いの親族関係さえ証明されていない。日本語も同様で、母音調和などの特徴だけでアルタイ諸語に属しているとは断定できない。それが本当のところのようだ。
南方系のオーストロネシア諸語と語彙、音韻体系が似ているとの指摘がある。だが語例が充分とはいえず、推定の域を出ないとされる。
中国語とは基礎語彙を共有せず、日本語には声調がなく系統的関連性は認められない。朝鮮語とは文法構造は似ているものの、基礎語彙が大きく異なり、有声無声の区別がないなど違いも大きい。
アイヌ語とは基礎語彙を共有するという指摘もある。だが、アイヌ語は膠着語ではなく包括語である。有声無声の区別もなく、両者の相違は大きい。系統的関連性を示す材料に乏しいという。
唯一、沖縄の言葉に系統的関連性を見出せる。ただ日本語の一方言(琉球方言)という説、琉球語として日本語族を構成するという説があり、研究者によって見解が分かれているらしい。
ちなみに、満洲語などツングース諸語、モンゴル語などのモンゴル諸語、トルコ語などのテュルク諸語をアルタイ諸語と呼ぶ。フィンランド語、ハンガリー語、サーミ語(スカンジナビア半島極北部の少数民族)、エストニア語(バルト三国のひとつ)などフィン・ウゴル語派とネネツ語などサモエード語派をあわせてウラル語族と呼ぶ。
以前は、ウラル-アルタイ語族を構成するという説もあったが、現在は否定されている。
比較言語学は18世紀に端を発している。インド-ヨーロッパ語族の系統関係解析という輝かしい業績をうち立てた。オーストロネシア諸語の解析にも活用された。
しかし、日本語を含むいわゆる孤立言語には太刀打ちできていない。系統関係が未解明なその他の多くの言語についても、比較言語学はインド-ヨーロッパ語族に対して発揮したような圧倒的な力を示せなかった。
たしかに日本語の系統関係は解明できず、今は八方ふさがりの状況にある。ただ、そんな中にも各種の努力は重ねられてきているようだ。幾つか紹介し、日本人がどこから来たか?を「言語学」的な側面から考察していこうと思う。
Ⅱ)言語年代学、語彙統計学、日本語混成言語説
ⅰ)スワデシュの言語年代学
まず言語年代学である。米国の言語学者モリス・スワデシュは基礎語彙という概念を導入した。言語は比較的一定の速度で変化すると仮定して、二つの言語が共通祖語から分岐した年代を算出する。
スワデシュは基礎語彙200語を選び出した。スワデシュ・リストという。基礎語彙とは幼年期初期に学習するような基礎的な単語で、時間経過に対して非常にゆっくりとしか変化しない。彼は各言語が基礎語彙をどの程度保持できるか比較検討した。
すると千年あたりの基礎語彙残存率は81%だった。それを保存率として計算すると、二つの言語間における基礎語彙共有率は、同系言語が祖語から分岐して1000年で64%となり、3000年で30%、6000年で10%をそれぞれ割り込む。10000年ではほとんどゼロに近づいた。
彼が英語、仏語、独語の三つをそれぞれ比較した結果は次の通りだった。英語-仏語間の残存率は27%、英語-独語間は60%、仏語-独語間で29%である。話し言葉や書き言葉を互いにたくさん借用していても、基礎語彙で比較するかぎり分岐年代を推定できるという劇的な結果だった。
この方法には批判がある。「言語が一定の速度で変化する」という前提そのものが成立しない。同根語であると判定するのがたいへん困難で、判断には恣意性がどうしても入り込む余地が残るなど。一般にスワデシュ・リストだけで二言語の近縁性を論じるようなことはできないとされるようになった。
しかし、この方法は重大なことを教えてくれる。基本的に、基礎語彙を共有しない言語間の系統解析は不可能に近い。分岐年代が非常に古い場合、すなわち10000年を超える言語どうしだと比較そのものができないということである。
逆に言うなら、基礎語彙を共有しない言語どうしの分岐年代は、10000年以上も前のことと推定して良いということである。日本語はほとんどの言語と基礎語彙を共有していないため、たとい類縁関係にあったとしても、分岐後10000年以上も経過したと考えられる。
別の解釈もある。「言語が一定の速度で変化する」という前提が否定される場合である。基礎語彙を共有しない言語どうしの比較では、どちらかの言語が(あるいは両方が)短期間のうちに劇的な変化を遂げた可能性がある。
たとえば異言語民族による征服があった場合、言語は短期間のうちに変化するだろう。言語そのものが完全に置き換わるケースと、基礎語彙を含む語彙が置き換わってゆくケースである。
これらは歴史上簡単に例を見出せる。清帝国の支配民族は満洲族だった。清朝では満洲語の他、漢語、モンゴル語が公用語だった。しかし現在モンゴル語は残っているが、満洲語は消滅し漢語に完全に置換された。
また朝鮮半島では、李朝朝鮮、日本による統治時代、その後の韓国と北朝鮮時代と、語彙が急速に置き換わっている。特に日本統治時代の影響を消し去るために、現在も国策として語彙の置換を進めている。もちろん基礎語彙の変化が起こりにくいことは確かであるが。
スワデシュリストは、
http://en.wikipedia.org/wiki/Swadesh_list
http://en.wiktionary.org/wiki/Appendix:Swadesh_list
を参照されたい。
ⅱ)安本美典の語彙統計学
日本の言語学者安本美典(やすもとびてん)は、スワデシュの手法を改良して語彙統計学をうち立てた。まずスワデシュ・リストを一部改変した。インド-ヨーロッパ語族にあっても日本語を含む他言語には存在しない前置詞など15語を入れ替えた。
安本の基礎語彙リストは、
http://www.geocities.jp/ikoh12/honnronn5/005_03/kisogoi200go-hyou.html
を参照されたい。
次に基礎語彙が二つの言語間で一致する度合いを調べた。一致が偶然によって起こったかどうかを統計的に明らかにしようと試みた。できるだけ恣意的解釈の入り込む余地がないよう、基準を決めコンピュータに入力して判定した。
比較する原則を次のように検討した。すなわち、
1)子音か母音かを問わず最初の音(sound)が一致するかどうかをS1検定とした(語頭音検定法)。
2)同様に最初と次の音が同時に一致するかどうかをS1S2検定とした。
3)最初と次とその次の三つの音が同時に一致するかどうかをS1S2S3検定とした。
4)以下、S1S2S3S4検定、S1S2S3S4S5検定、S1S2S3S4S5S6検定など。
また、
5)最初の子音(consonant)が一致するかどうかをC1検定とした(第一子音検定法)。
6)最初と次の子音が同時に一致するかどうかをC1C2検定とした。
7)最初と次とその次の三つの子音が同時に一致するかどうかをC1C2C3検定とした。
8)以下、C1C2C3C4検定、C1C2C3C4C5検定、C1C2C3C4C5C6検定など。
安本は、日本語のような孤立言語と他の言語とを比較するためには、S1検定、S1S2検定、S1S2S3検定が有効であることを実証的に突き止めた。また淡い系統関係の検出には、S1検定とC1検定が最も優れていることを明らかにした。
次に示すのはS1(語頭音)検定法で得られた結果である。すなわち語頭の音が一致した場合に、それが子音、母音を問わず、その語彙は共通していると見なす方法を用いた。
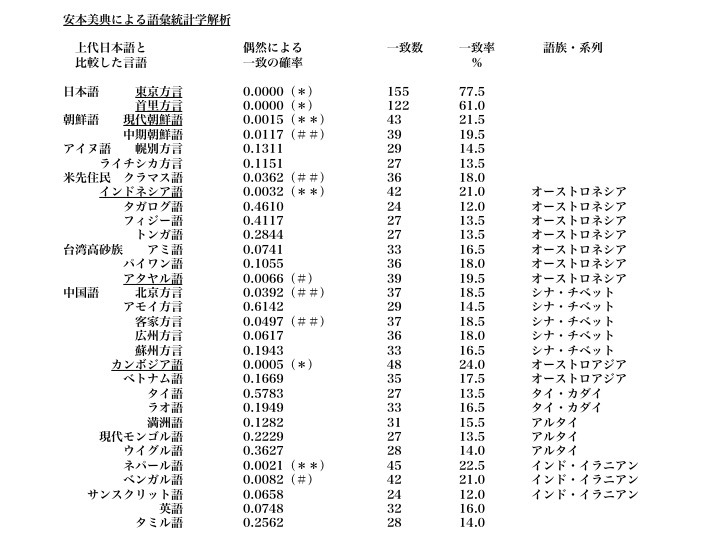
安本美典の語彙統計学による解析結果
語頭の音との一致が偶然によって得られる確率がゼロに近いほど、当該言語は「上代日本語(奈良時代の日本語)」に近いと言える。*:0.1%水準で有意、**:0.5%水準で有意、#:1%水準で有意、##:5%水準で有意、すなわち確率的に偶然では一致が得られにくいことを意味する。より大きな図はこちら
安本美典著「日本語の起源を探る」より一部改変。
スワデシュの言語年代学と安本の語彙統計学のまとめはこちらを参照されたい。
詳しいデータはダウンロードNaraJapaneseOtherLanguages.xlsxを参照されたい。安本による表を一部改変。
上図に示された結果は次のとおりである。
1)日本語もスワデシュの算出した世界の言語残存率とほぼ同じく1000年で77.5%であった。
2)首里方言は基礎語彙が偶然に一致したとは考えられない。
3)カンボジア語は有意水準0.1%で偶然の一致とはいえないほど、上代日本語と似ている。
4)現代朝鮮語、インドネシア語、ネパール語の三つは有意水準0.5%で、台湾原住民アタヤル語、ベンガル語は有意水準1%で偶然の一致とは考えにくい関係にある。
5)北京方言、客家方言、中期朝鮮語、米先住民クラマス語とは、有意水準5%で偶然の一致とは考えにくい。
より詳しい解析をしたところ、日本語、朝鮮語、アイヌ語の三言語には、偶然の一致とは見なせない関係が認められた。その結果はダウンロードNaraJpnMdJpnAinuKor.xlsxを参照されたい(安本による表を一部改変)。数字は偏差値を表す。値が大きいほど強い関係を示す。*印は2.33以上で、2.33以上ならば1%有意水準で偶然による一致とは言えない。2.33に相当する位置を薄青色の実線で表した。
上代日本語とアイヌ語幌別方言の関係は、S1検定、C1検定では偶然による一致としか見なせなかった。しかしS1S2、S1S2S3検定、ならびにC1C2、C1C32C3検定を使うと一致が偶然によるとは見なせなかった。平均をとっても偏差値3.526と、1%水準の偏差値2.33を越えていた。
現代日本語東京方言と現代朝鮮語は、S1、C1、C1C2、C1C2C3検定法で偶然による一致を越えた関係性が認められた。中期朝鮮語とアイヌ語幌別方言の関係は、C1検定法で偏差値3.303と偶然による一致とは見なせないという結果をしめした。
カンボジア語(モン・クメール語)はオーストロアジア諸語、インドネシア語はオーストロネシア諸語に属する。安本はオーストロアジア諸語、オーストロネシア諸語の一部が日本語の語彙形成に大きな影響を及ぼしたと考えた。
カンボジア語、インドネシア語と上代日本語の間で基礎語彙が共有されているからである。上図にまとめたように、偶然の産物である確率がそれぞれ0.1%と0.5%とたいへん低い。
ネパール語、ベンガル語の基礎語彙が日本語と似ているのは、日本語の成立に影響を与えた言語がネパール語やベンガル語にも影響を与えたからだろう。
上代(奈良時代)日本語とビルマ系ボド語の基礎語彙、特に身体に関する語を比較したのが次の図である。参考までに英語と独語、仏語の比較も示してある。
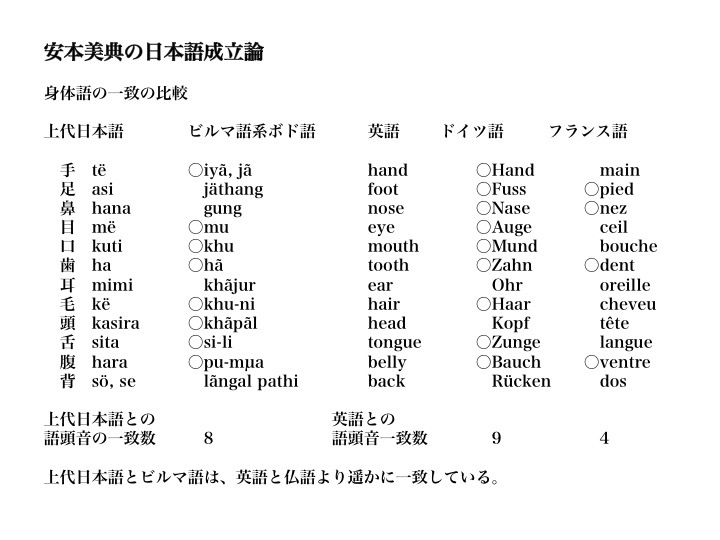
安本美典の日本語成立論:日本語とビルマ語の基礎語彙一致
安本美典著「日本語の起源を探る」より一部改変。
倭人語が日本列島を言語的に統一していく過程で、
オーストロネシア系諸語の語彙が取り入れられた。
歴史時代に入っては、中国語の大きな影響を受けながら
現代日本語を形成するようになった。安本はこのように考えた。
より大きな図はこちら
上代日本語とビルマ系ボド語を比べた時、手(tê)とiyâがなぜ一致するのか素人には理解しにくいものの、その他、目(mê)とmu、口(kuti)とkhu、歯(ha)とhâなど、両者の類似点が非常に分りやすい。
その一致度は12単語中8語だという。英語と独語の一致数9語に迫るほどで、英語と仏語の間の4語をはるかに超えている。
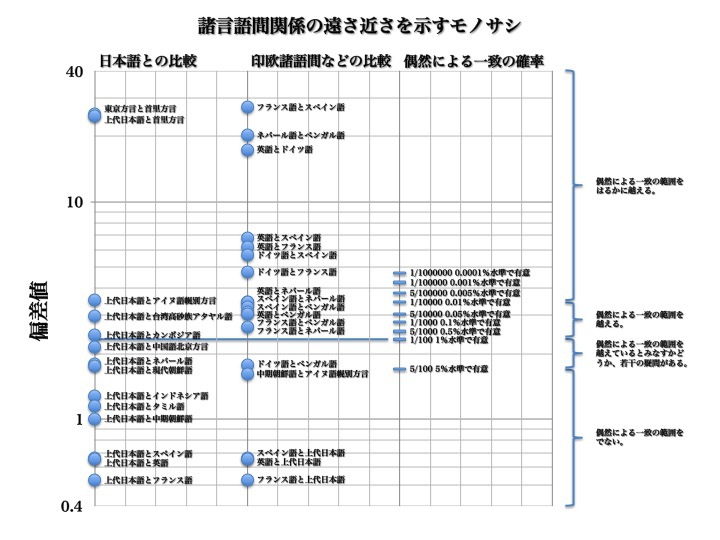
諸言語間関係の遠近をはかるモノサシ
数字は偏差値を表す。値が大きいほど強い関係を示す。*印は2.33以上で、2.33以上ならば、偶然による一致とは言えない(1%有意水準で)。
より大きな図はこちら
この図は、S1、S1S2、S1S2S3、C1、C1C2、C1C2C3検定の平均値で、二言語間の遠さ近さを測っている。
危険率1%で有意と判定されるなら、すなわち偏差値2.33以上だと「偶然による一致の範囲を越える」と考えた。0.01%水準で有意なら「偶然による一致の範囲をはるかに越える」関係性があると認めた。
ただし安本は、危険率5%で有意と判定されても、偶然による一致の範囲を越えているとみなすかどうか、若干の疑問があるとした。
現代日本語東京方言と首里方言、上代日本語と現代日本語首里方言、上代日本語とアイヌ語幌別方言には、偶然による一致の範囲を越えた関係性が認められた。さらに上代日本語と台湾高砂族アタヤル語、上代日本語とカンボジア語にも偶然とは考えられない関係が存在することが判明した。
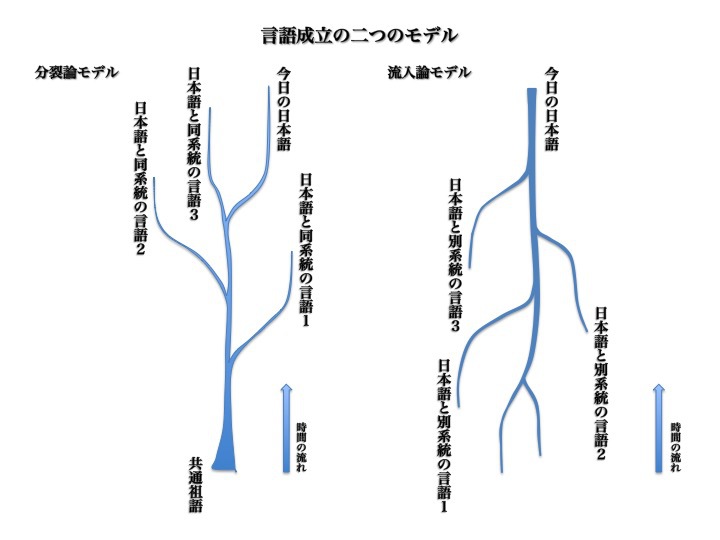
安本は実証研究から次のような「流入論モデル」を提唱した。ヨーローッパ諸言語がラテン語を祖語とした「分裂論モデル」であるのと対照的である。

言語形成の二つのモデル
安本美典「日本語の起源を探る」より一部改変。
図左はラテン語を共通祖語としてヨーロッパ諸言語が樹状に分かれていった分裂論モデル。図右は日本語とは別系統のインドネシア語、クメール語、ビルマ系江南語、中国語北京方言から基礎語彙がどんどん流入して河川のように合流する流入論モデル。
日本語形成の二つのモデル
安本美典「日本語の起源を探る」より一部改変。
本図は前の図よりも一般化して描いたもの。図左は共通祖語から日本語と同系統の他言語が樹状に分かれていった分裂論モデル。図右は日本語とは別系統の言語から基礎語彙がどんどん流入して河川のように合流する流入論モデル。
安本は次のようにも考えた。最終氷期つまり後期旧石器時代、日本列島が大陸と地続きだったころ、一つの基語が日本海を囲むようにして存在していた。この基語を「古極東アジア語」と呼んだ。あるいは「環日本海語」と呼んでも良いだろう。
氷期が終わる頃、日本列島が大陸から切り離されてゆく。その過程で、古日本語、古アイヌ語、古朝鮮語は次第に方言化していった。時代が下ると、全く別の言語として互いに通じ合わないほどになっていった。
こうして考えると、互いに孤立言語と考えられていた日本語、アイヌ語、朝鮮語の三言語は、語彙統計学の立場からは「古極東アジア語」「環日本海諸語」とひとくくりにできるだろう。
前述の流入論モデルと整合性をつけて理解するために、本稿では日本語の成立を次のようなモデルで考えることにする。
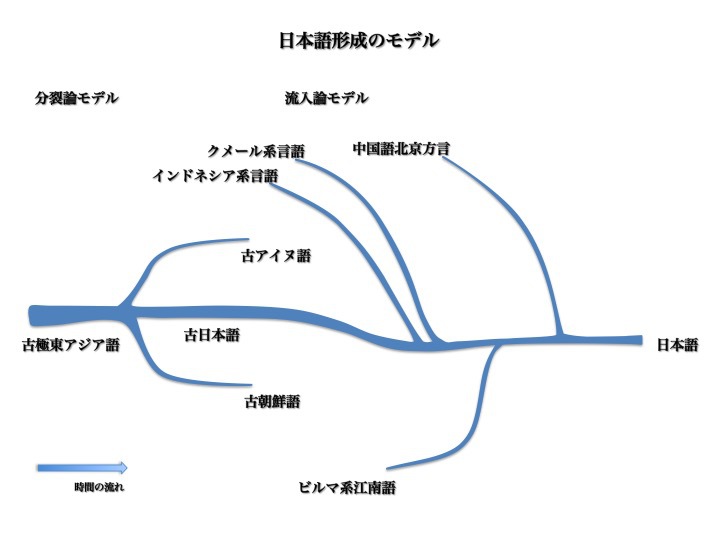
日本語成立のモデル
分裂論および流入論モデルを組み合せて描いた日本語成立に関する仮説。安本の「流入論モデル」と「古極東アジア語仮説」を組み合せた統合モデル。
まず古極東アジア語から古日本語、古アイヌ語、古朝鮮語が分裂した。ここまでは分裂論モデル。
その後古日本語は台湾高砂族アタヤル語、インドネシア語、カンボジア語の系列言語から基礎語彙を取り入れた。さらに客家方言、ビルマ系江南語、中国語北京方言、梵語(ネパール語系サンスクリット語)の影響も受けて大和言葉(上代日本語)が成立した。以上が流入論モデルである。
ⅲ)崎山 理の日本語混成言語説
崎山 理(さきやま おさむ)は日本語混成言語説を唱えた。まず日本語とツングース諸語の共通点と相違点を列挙する。
日本語とツングース諸語の共通点はよく知られている通りである。SOVという語順が一致すること、助詞や助動詞が存在することだ。
相違点としては、まず多くの語彙が共通していないことが挙げられる。他に、接辞法(お寺、ま昼、か細い、い抱くなどの接頭語)がツングース諸語には存在しないことである。これらが主な相違点だ。
それら相違点は、日本語とオーストロネシア諸語の共通点でもある。しかも日本はツングース諸語とオーストロネシア諸語が話されている地域のちょうど中間に位置する。

崎山 理の日本語混成言語説
崎山 理著「日本語の形成」より
より大きな図はこちら
語彙の比較は上図を参照されたい。縄文語と原オーストロネシア語の再構成型を比較して、似ていると考えられた主な例は次の通りである。
縄文語の「a」=「我」と原オーストロネシア語の「a/áku」=「私」。
以下同様に、
「asu」=「朝、明日」と「qa(n)so」=「日、日光」、
「baku」=「箱」と「bakul」=「編籠」、
「ine」=「母」と「ina」=「母」、
「iwa」=「魚」と「iwak」=「魚」、
「-ni」=「に」と「n-i」(属格など)、
「piri-」=「拾う」と「piliq」=「選ぶ」。
縄文語と原ツングース語の再構成型を比較し、似ていると考えられた主な例も挙げている。上記と同様に、
「-ba/-bo」=「わ(=は)、を」と「-ba/-b∂」(対格、詠嘆)、
「kuri」=「クリ」と「kuri」=「灰色、雑色」。
崎山は、上代日本語の八割がオーストロネシア語由来と考えて良いと述べている。上記の解析などから、彼は次のような日本語混成言語説を唱えた。
今から五千年前頃、縄文時代中期までに、ツングース語を話す人々が東日本を中心に住んでいた。アイヌ語を話す人々と共存していた。北方(樺太、沿海州、シベリア東端)ツングース系の人々が南下して北海道、東北、関東地方を中心に住みついた。
そこに、日本の南部にオーストロネシア語を話す人々が移住して来た。南方(東南アジアなど)オーストロネシアン系の人々が北上して沖縄、九州から近畿地方にかけて住みついた。
交流が始まり、通婚する者があらわれ、その混血集団の村もできる。第一段階として言葉のピジン語化が起こった。オーストロネシア語を話す人々の移住がその後幾波も重なり、古墳時代まで続いた。こうしてツングース語とオーストロネシア語がクレオール化した。
ピジン語化とは文法の発達が不十分で、発音や語彙の個人差が大きく、複雑な意思疎通が不可能な共通語化を言う。またクレオール語化とは文法、発音、語彙が発達および統一し、複雑な意思疎通が可能になった共通言語化を言う。
SOV型の基本語順ではツングース語が残り、語彙や接頭辞などではオーストロネシア語が用いられるようになったというわけである。
大陸から中国文化を携えた人々もやって来て語彙の一部を借用することはあったが、言語体系に影響を与えることにはならなかった。崎山は、以上のように日本語が成立したと考えた。
Ⅲ)言語類型地理論
ⅰ)松本克己の言語類型分類と地理学
言語類型論という分野がある。世界中の言語の特徴を収集し、その相違点、類似点を探ってゆく。最終的に、すべての言語に普遍的な要素を見つけだそうという学問である。
歴史的系統関係、地理的分布を組み合せると言語類型論とは言えなくなるのだそうだ。しかし松本克己は、言語類型分類学と地理学を結びつけて、日本語の系統関係を考察した。彼の切り開いた分野は言語類型地理論と呼ばれる。
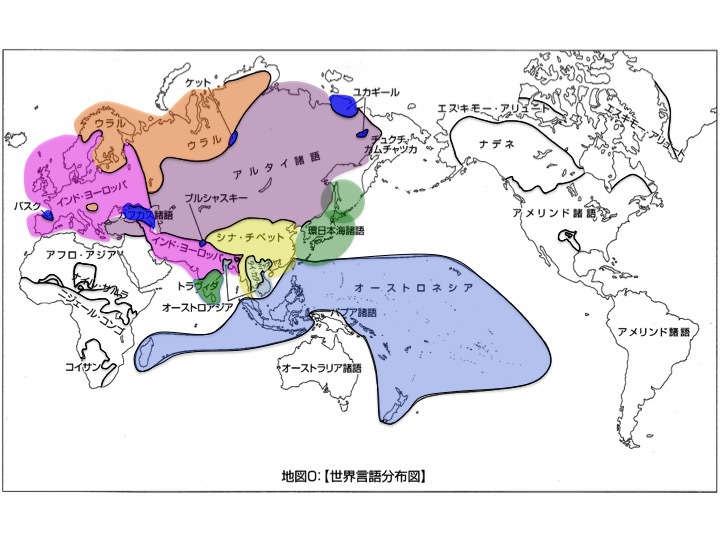
そもそも歴史言語学、比較言語学から世界の言語は次の図のように分布すると考えられている。ヨーロッパ人の南北アメリカ大陸への移住、漢族の東南アジアや世界各地への展開などが起こる前、すなわち先史時代を対象とした分布である。
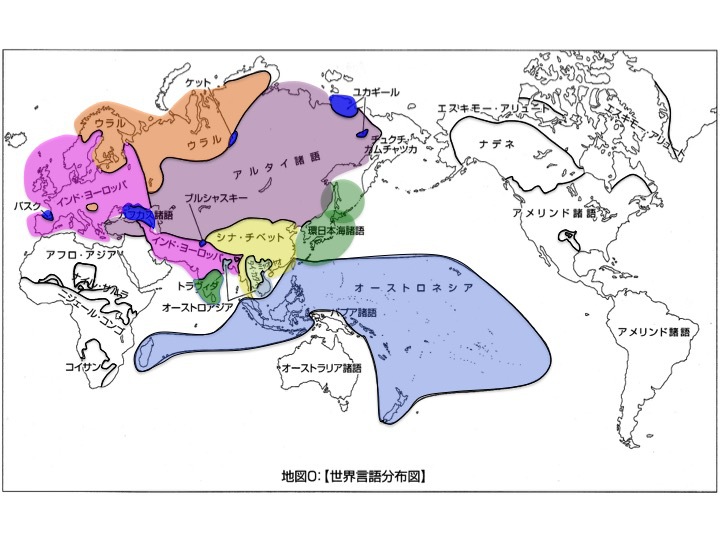
世界言語分布
松本克己著「世界言語のなかの日本語」より改変
より大きな図はこちら
ユーラシア大陸内陸に分布する語族、諸語は
インド-ヨーロッパ語族、
ウラル語族、
アルタイ諸語、
チベット語族、
ドラビダ語族。
ユーラシア大陸沿岸に分布するのは、
太平洋沿岸南方系オーストリック大語族に属する
オーストロアジア諸語、
オーストロネシア諸語、
ミャオ-ヤオ諸語、
タイ-カダイ諸語、
シナ語、
太平洋沿岸北方系の諸語に属する
日本語、
朝鮮語、
アイヌ語、
ギリヤーク語(アムール地方)。
これら太平洋沿岸北方系諸語を松本は「環日本海諸語」と呼んだ。
その他、孤立言語、点在言語とされる
バスク語、
カフカス諸語、
ケット語、
ユカギール語、
ブルシャスキー語、
周辺境界群とされる
チュクチ-カムチャッカ諸語、
エスキモー-アリュート諸語などである。
大洋州に存在するのが
パプア諸語、
オーストラリア諸語。
南北アメリカ大陸に分布するのが、
エスキモー-アリュート諸語、
ナ-デネ諸語、
アメリンド諸語。
アフリカおよびアラビア半島に分布するのが、
アフロ-アジア諸語、
ナイル-サハラ諸語、
ニジェール-コンゴ諸語、
コイサン諸語である。
これら膨大な言語の類型、すなわち特徴を互いに比較してゆくのである。松本が各言語の比較に用いた「類型」「特徴」を次の図にまとめた。

松本克己の言語類型地理論による「言語の特質」
松本克己著「世界言語のなかの日本語」より改変
より大きな図はこちら
1)流音(ラ行音)_RとLを区別するか?一種類しか持たないか?
__________複式:rightとlight
__________単式:日本語のR音
2)形容詞_____名詞の仲間、体言型か?動詞の仲間、用言型か?
__________体言型:beauty→beautiful
__________用言型:美し・く、き、けれなどと活用
3)名詞の数____複数標示が義務化されているか?
__________義務化されていないか?
__________義務化:boys、catsなど
__________非義務化:日本語。
_____________「子供ら」などはあるが義務ではない
4)名詞の類別___性別で分類されているか?
__________数え方で間接的に分類されるだけか?
__________名詞類別型:ship→she
5)数詞の類別___数え方で対象物(名詞)を類別するか?
________________________しないか?
__________数詞類別型:一冊・二冊、
________________一匹・二匹、
________________一人・二人など
6)包括除外___「私たち」に聞き手が除外されているか?
___________________含まれるか?
マレー語:聞き手を除外した私たち=kami、
_______________1&2人称で聞き手を包括=kita
7)重複造語法___重複造語法のない言語か?
__________重複造語法を多用する言語か?
__________重複なし型:一般的にはない。ただし
________________papa、mama、
________________moo-mooなどは例外
__________重複活用型:山々、高々、泣く泣くなど
8)動詞の人称標示_主語目的語人称を動詞で標示する言語か?
__________主語人称だけを標示する言語か?
__________全く標示しない言語か?
__________多項型:アイヌ語
______________eenkore(e-en-kore)
_____________(汝-我に-与える)
__________単項型:I like ~、He likes ~
__________無標示型:私は好きだ、彼は好きだ
9)名詞の格標示__目的語(対格)を標示して文を構成する言語か?
__________被動者に何かが行われた時のみ
__________行為者に標識が付けられる能格言語か?
__________格標示を欠いていてどちらとも取れる言語か?
__________格標示を欠いていて語順だけで表す言語か?
__________対格型:母が娘を愛する
__________能格型:バスク語
______________ama-k(能格 母が)
______________alaba(絶対格 娘)
______________maite-du(他動詞 愛する)
__________中立型A:アイヌ語
_______________hapo(無標格 母)
_______________matnepo(無標格 娘)
_______________nukar(他動詞 見た)
__________中立型B:語順で区別
_______________The dog(主語)
_______________chases(動詞)
_______________the cat(目的語).
順を追って説明し、類型ごとの諸言語世界分布を見てみよう。
1)流音タイプによる言語分布
流音、すなわち「ラ行音」、RとLを区別するか?一種類しか持たないか?という類型である。区別するタイプを複式、区別しない言語を単式と呼ぶ。日本語はR音のみの単式。英語はR音とL音を区別する複式である。
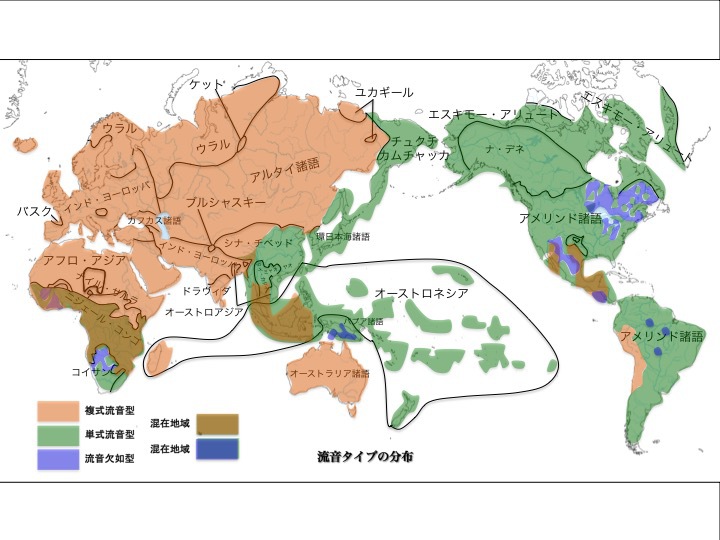
流音(「r(アール)」「 l(エル)」)タイプによる言語分布
松本克己著「世界言語のなかの日本語」より改変
より大きな図はこちら
図のオレンジ色が複式、緑色が単式を表す。ユーラシア大陸の大部分、アフリカ大陸北部の諸言語とオーストラリア諸語などが複式である。環太平洋地域であるユーラシア大陸太平洋沿岸部、オーストロネシア諸語、南北アメリカ大陸の大部分が単式であることがわかる。
複式と単式が混在している地域もある(茶色)。流音が欠如している地方の諸語もある(うす紫色)。単式と流音欠如の言語が混在している地域もある(濃い紫色)。
2)形容詞タイプによる言語分布
形容詞タイプは体言型と用言型に分けられる。体言型とは名詞の仲間であり、用言型とは動詞の仲間である。
体言型は英語に代表される。名詞である「beauty(美しさ)」が形容詞の「beautiful(美しい)」となる。用言型は日本語に代表される。「美し」「美しく」「美しき」「美しけれ」などと、動詞のように活用型が存在する。
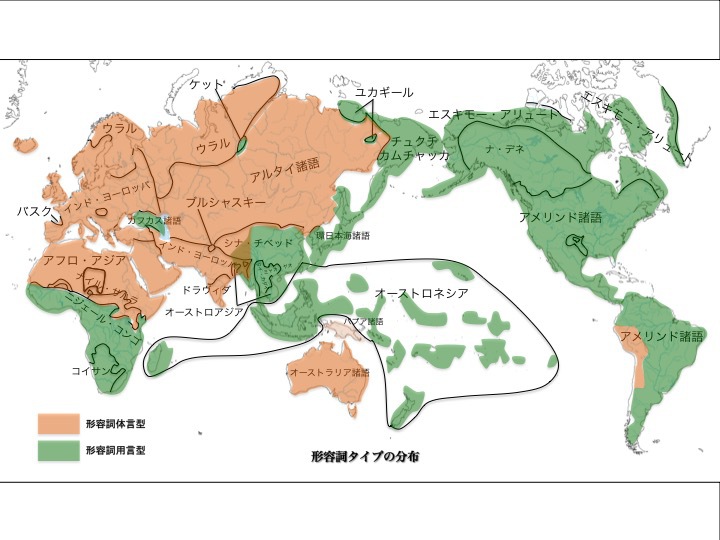
形容詞タイプ(用言型と体言型)による言語分布
松本克己著「世界言語のなかの日本語」より改変
より大きな図はこちら
流音タイプとほぼ同様、体言型がユーラシア大陸の大部分、アフリカ北部、オーストラリア諸語であり(オレンジ色)、用言型がユーラシア大陸太平洋沿岸部、オーストロネシア諸語、南北アメリカ大陸の諸語のほとんどである(緑色)。
アフリカ大陸南部、マダガスカル、カフカス諸語が形容詞タイプである(緑色)のは、流音タイプの分布と異なる傾向を有する。
3)名詞複数形標示による言語分布
名詞の複数標示が義務化されているか?義務化されていないか?世界の言語はどちらかに分類できる。
言うまでもなく英語は義務化(文法化)されている。「boys」「cats」など。日本語は義務化されていない。「子供」は一人か複数か明示しない。ただし「子供ら」など複数表現方法はある。しかしながら義務ではない。
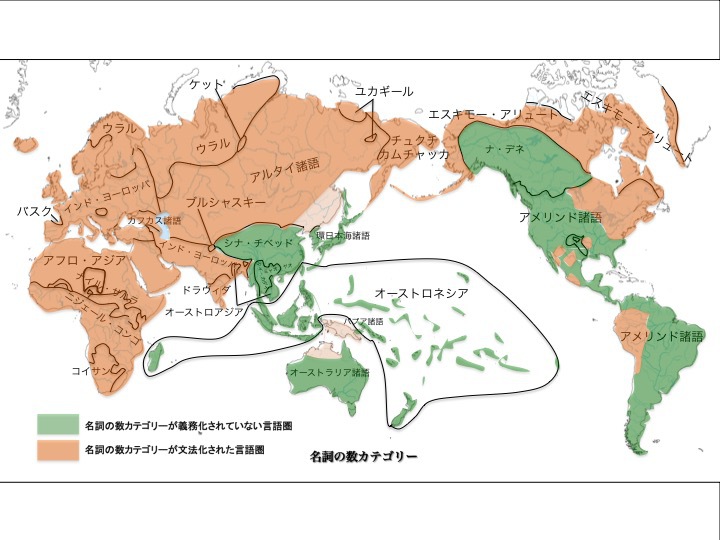
名詞複数形標示の義務・非義務による言語分布
松本克己著「世界言語のなかの日本語」より改変
より大きな図はこちら
世界の言語の大部分は義務化(文法化)されている(オレンジ色)。ユーラシア大陸の太平洋沿岸部の諸語、オーストロネシア諸語、南北アメリカ大陸の諸語の大部分が名詞複数標示が義務づけられていない(緑色)。日本語は義務化されていない言語圏に属する。
4)5)名詞類別による言語分布
名詞を性別などで分類するか?しないか?という類型である。ドイツ語は分類する。「der Vater(父、男性名詞)」「die Mutter(母、女性名詞)」「das Kind(子ども、中性名詞)」など。英語はずいぶん薄らいではいるが「ship(船)」を「she(彼女)」で受けるなど、名詞類別型に属するとされる。
他方、呼び方で間接的に分類される場合もある。日本語で「誰」「何」と人間・非人間を区別したり、「いる」「ある」と有生・無生を区別する類いである。
数え方で対象物(名詞)を類別するか?しないか?という分類項目もある。日本語ではわかりやすい。一冊・二冊、一匹・二匹、一人・二人などである。英語などにはない。
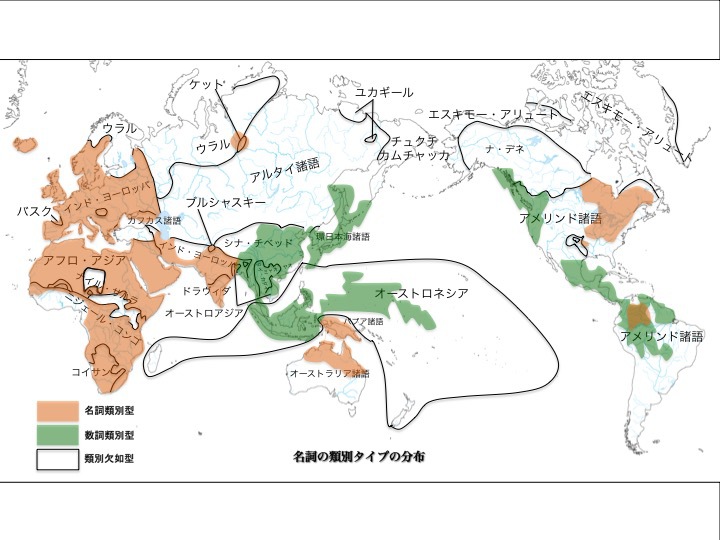
名詞を性などで類別するか数詞(一匹、二人など)で類別するかによる言語分布
松本克己著「世界言語のなかの日本語」より改変
より大きな図はこちら
図にあるように、名詞を性などで分類する言語(オレンジ色)、数詞で類別する言語(緑色)、どちらの類別も欠如している言語(無色)が世界には分布している。
数詞で類別するタイプには日本語、朝鮮語、漢語、オーストロネシア諸語を含む、ユーラシア大陸太平洋沿岸部の諸言語が挙げられる。
6)包括人称による言語分布
「私たち」に聞き手が除外されているか?含まれるか?を区別することのある言語と、全く区別しない言語が存在する。「私ども」「手前ども」は、通常聞き手を含まないが、日本人同士の間で「我々日本人は」と語る場合の「我々」は聞き手を含んでいる。
著しい例を挙げると、マレー語では一人称と二人称の他に、一+二人称代名詞が存在する。それを包括人称と呼ぶ。聞き手を除外した私たちは「kami」であり、一+二人称で聞き手を包括した場合が「kita」という具合である。
他方、英語などでは一人称と二人称が同時に関与することは有り得ない。包括人称を完全に欠如している例である。
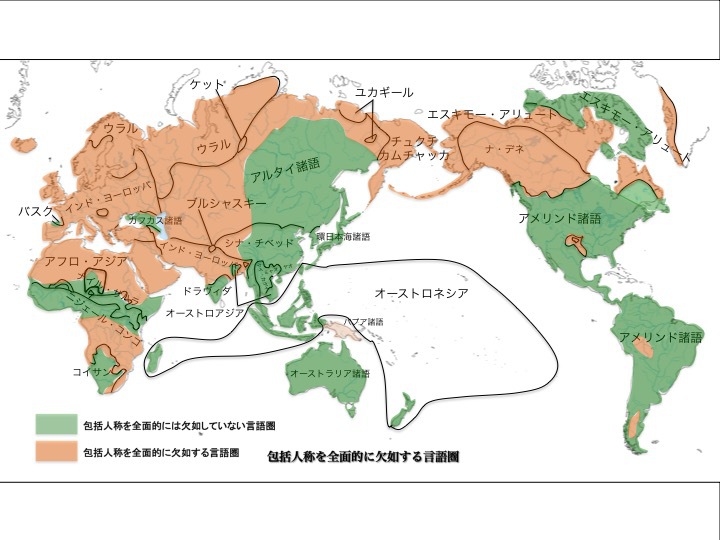
包括人称を欠如するかどうかによる言語分布
松本克己著「世界言語のなかの日本語」より改変
より大きな図はこちら
英語など包括人称を完全に欠如している言語の分布がオレンジ色で示されている。緑色は包括人称を完全には欠如してない言語の分布である。日本語は後者、すなわち包括人称を完全には欠如していない言語圏に属する。
7)重複造語法による言語分布
重複造語法とは、日本語のように「山々」「高々」「泣く泣く」など、単語を重複させて(活用して)関連する単語を作ってゆく特徴である。そういった重複造語法を多用する言語か?重複造語法のない言語か?で分類する。
ただし重複なし型の言語でも「papa(お父ちゃん)」「mama(お母ちゃん)」「moo-moo(ハワイで正装とされる女性用のゆったりしたドレス)」などが例外的に存在する。
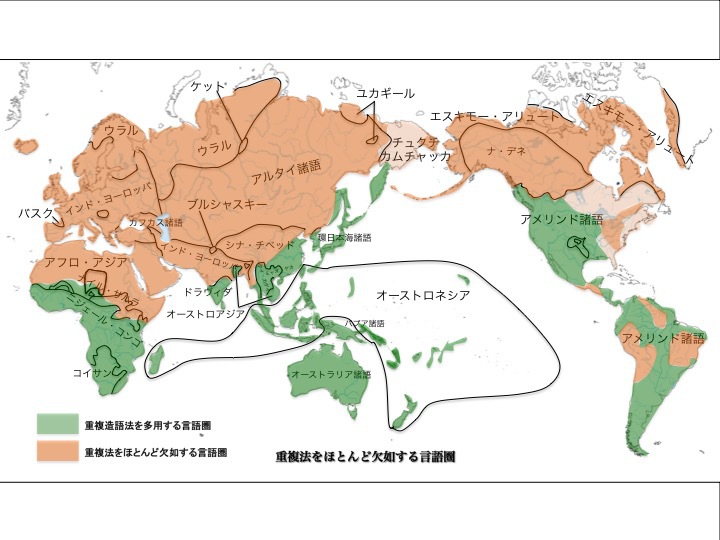
重複造語法を欠如するかどうかによる言語分布
松本克己著「世界言語のなかの日本語」より改変
より大きな図はこちら
図に分類するように、重複造語法を多用する言語(緑色)とほとんど欠如する言語(オレンジ色)グループが存在する。
8)動詞人称標示タイプによる言語分布
日本語の動詞は主語でも目的語でも人称にほとんど無関係である。「私は好きだ」「彼は好きだ」などの通りである。他言語の動詞では主語の人称を標示したり、目的語の人称を標示する場合がある。
英語では「I like ~(私は~が好きだ)」「he likes ~(彼は~が好きだ)」のように三人称単数で形が変わる。これを「動詞が主語の人称を標示している」という。ドイツ語では「ich liebe ~(私は~を愛する)」「du liebst ~(お前は~を愛する)」「er liebt ~(彼は~を愛する)」と動詞の語尾変化が主語の人称に一致する。
アイヌ語では「eenkore(e-en-kore)」(汝-我に-与える)など、動詞が主語の人称と目的語の人称を標示する。
日本語などは「無標示型」、英語やドイツ語などは「単項型」、アイヌ語などは「多項型」の動詞人称標示タイプであると表現する。
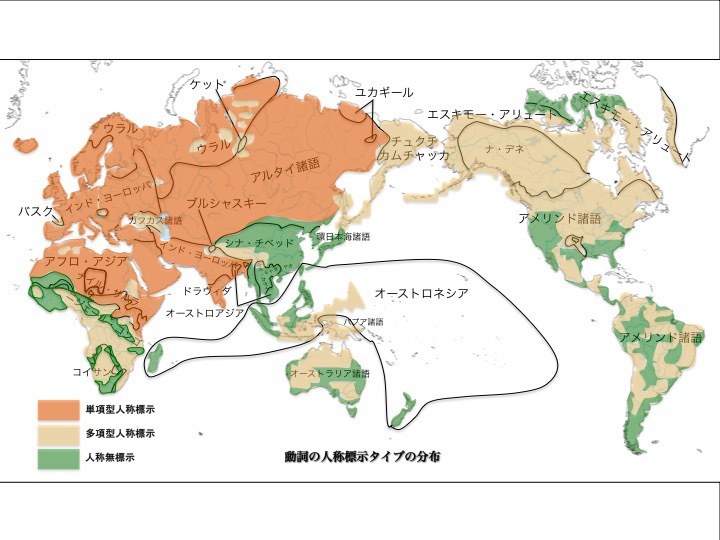
動詞の人称標示タイプ(単項、多項、無標示)による言語分布
松本克己著「世界言語のなかの日本語」より改変
より大きな図はこちら
図にあるように、ユーラシア大陸の大部分とアフリカ大陸北部の諸言語が単項型人称標示タイプに属する言語(オレンジ色)、ユーラシア大陸太平洋沿岸南部やオーストロネシア諸語の一部、南北アメリカ大陸の一部、アフリカ大陸の一部、オーストラリア大陸の一部地域が人称無標示タイプに属する言語(緑色)、残りが多項型人称標示タイプの言語(茶色)である。
9)名詞格標示による言語分布
動詞の人称標示に密接に関係する文法減少として名詞の格標示がる。主語、目的語の文法関係を、名詞に接辞や接置詞などを付けることにより明示的に表現するかどうかである。大別して、「対格型」「能格型」「中立型」という三タイプに分類できる。
「対格型」は、日本語やラテン語に代表される。「母が来る(自動詞)」「母が娘を愛する(他動詞)」のように、自動詞と他動詞の主語を同じ格で表し、他動詞の目的語を特別の格(目的格)で標示する。
ラテン語では「mater venit(母が来る)」「mater filiam amat(母が娘を愛する)」となり、日本語にほぼ対応する。
対して「能格型」では、自動詞の主語と他動詞の目的語を同じ格(絶対格)で標示する。他動詞の動作主を別の格で標示し、その格を「能格」と呼ぶ。
その典型がバスク語で「alaba dator(娘が来る)」「amak alaba maitedu(母が娘を愛する)」となり、自動詞の主語「alaba(娘が)」と他動詞の目的語「alaba(娘を)」が同じで、絶対格と呼ばれる。
他動詞の主語が能格と言って「amak(母が)」という特別の格で標示する。エスキモー語でも「panik itertuq(娘が来る)」「aanam panik kenkaa(母が娘を愛する)」となる。バスク語では「-k」、エスキモー語では「-m」が能格の標識である。
一方、「中立型」は名詞の側では首尾一貫して形態を変化させず、区別しないタイプである。英語やアイヌ語がその例である。
英語では「The dog chases the cat(犬が猫を追いかける)」「The cat chases the dog(猫が犬を追いかける)」など名詞の形は全く同じで、語順により主語か目的語かを区別している。
アイヌ語でも「hapo(母)matnepo(娘)nukar(見た)」など名詞の形が同じである。ただし、他動詞の主語と目的語が同じ三人称単数の場合、両者を形の上で区別できない。クリー語という言語では、動詞の形で主語と目的語を区別しているため、アイヌ語のような曖昧さがないという。
松本は、アイヌ語やクリー語のようなタイプを「中立型A」、英語のようなタイプを「中立型B」と呼んだ。
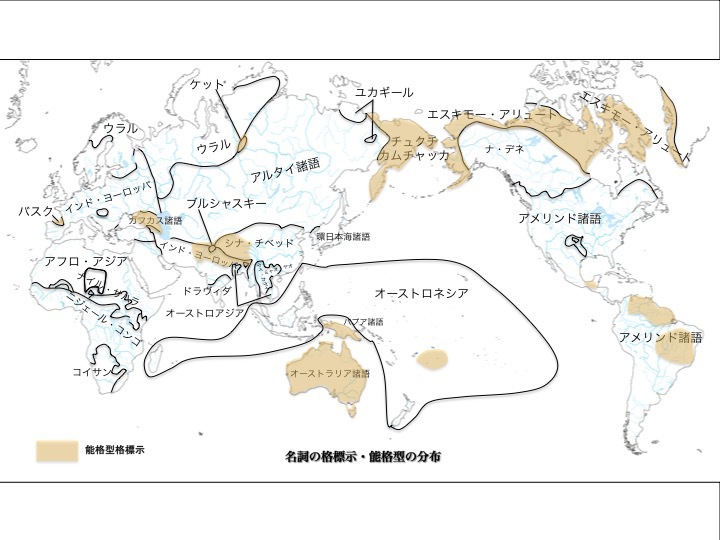
名詞の格標示による言語分布:能格型の分布
松本克己著「世界言語のなかの日本語」より一部改変
より大きな図はこちら
図では能格型格標示を有する言語がオレンジ色で示されている。日本語は対格型であり、能格型格標示の特徴を有しない。
ⅱ)松本克己の言語類型地理論
松本は上記の九項目にわたる特徴を使って、世界の言語分布を次の二つの図のように分類した。本稿ではアフリカ大陸の諸言語は省略している。最初の図がユーラシア大陸、オセアニアの諸言語で、次の図が南北アメリカ大陸の諸言語の言語類型である。
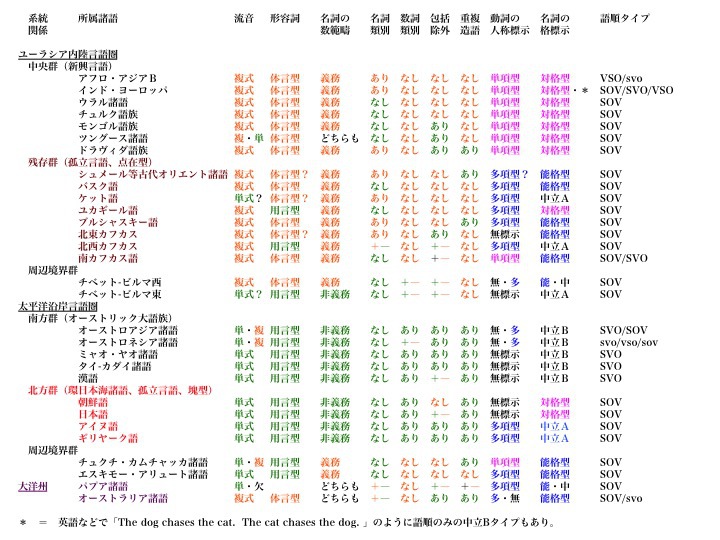
類型的特徴の地域・語族分布(ユーラシア、オセアニア)
松本克己著「世界言語のなかの日本語」より改変
より大きな図はこちら
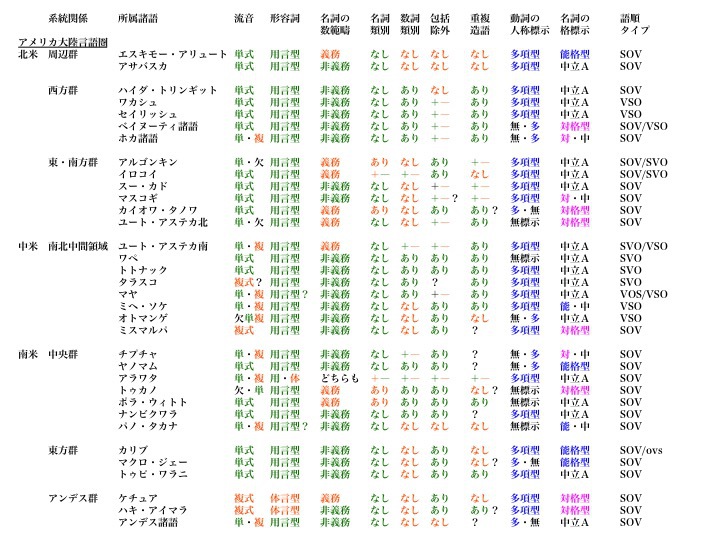
類型的特徴の地域・語族分布(アメリカ大陸)
松本克己著「世界言語のなかの日本語」より改変
より大きな図はこちら
大きな視点で分類すると、ユーラシア大陸内陸言語圏(オレンジ色)と太平洋沿岸言語圏(緑色)の二つとなる。分類の元になっている類型が、1)~7)の流音タイプ、形容詞タイプ、名詞の数範疇、名詞類別、数詞類別、包括人称除外、重複造語である。
ユーラシア大陸内陸言語圏の諸言語は、
流音タイプ___複式
形容詞タイプ__体言型
名詞の数範疇__義務
名詞類別____あり(が多い)
数詞類別____なし
包括人称除外__なし(が多い)
重複造語____なし(が多い)
という特徴を持つ。
太平洋沿岸言語圏の諸言語は、
流音タイプ___単式
形容詞タイプ__用言型
名詞の数範疇__非義務
名詞類別____なし
数詞類別____あり
包括人称除外__あり(が多い)
重複造語____あり
という特徴を持つ。
南北アメリカ大陸の諸言語も、ユーラシア大陸太平洋沿岸言語圏と同様に、
流音タイプ___単式(が多く)
形容詞タイプ__用言型(が多く)
名詞の数範疇__非義務(が多く)
名詞類別____なし(が多く)
数詞類別____ありなし(半々)
包括人称除外__あり(が多く)
重複造語____あり(が多い)
という特徴を持つ。
ただし、北米大陸西部はユーラシア大陸太平洋沿岸言語圏と似た傾向が強く(緑色が北米大陸西部、中米に多く分布)、中部や東部はユーラシア大陸内陸部の古い言語層とつながる傾向が垣間見えている(オレンジ色が北米大陸中部と東部あるいは北部に多く分布)。
こうした特徴を、松本は当時の分子遺伝学的解析結果と組み合せてみた。一九九四年、遺伝子の主成分の一つがアメリカ大陸を含めた周辺地域に遺伝子拡散したが、その中心地域が日本海域だったのではないかと発表された。
こういった仮説はその後の研究で検証、修正されてゆくのだが(YdnaハプログループCの亜型解析など:後述する)、今から一万二千年以上前の後期旧石器時代、海面水準は現在より約百メートル程度の低下しており、日本列島とその周辺は現在と全く違った地形だった。
日本列島は北方で大陸と完全につながり、東シナ海も陸地と化して列島に間近に迫り、日本海は今よりはるかに狭い内海だった。
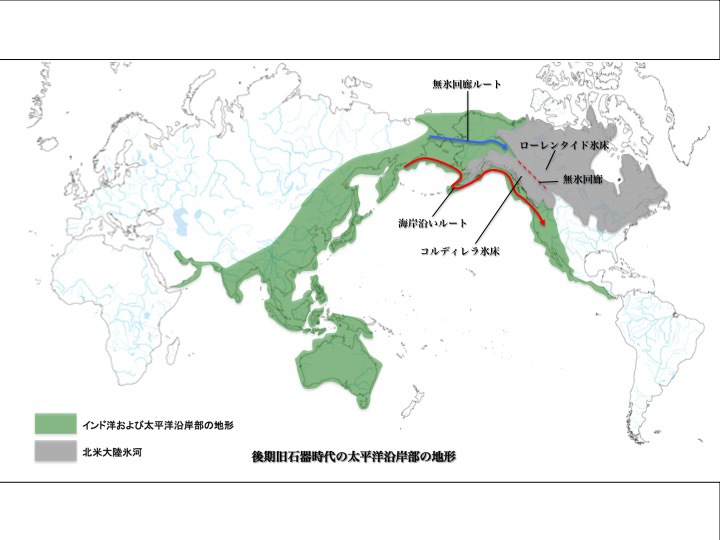
後期旧石器時代の太平洋沿岸部地形
松本克己著「世界言語のなかの日本語」より改変
北米大陸の氷床、コルディレラ氷床とローレンタイド氷床、無氷回廊(赤点線)、海岸沿いルート(赤実線)、無氷回廊ルート(青実線)が示されている。
より大きな図はこちら
一方、後期旧石器時代の北米大陸は、およそ一万八千年前をピークとする最終氷河期最寒冷期、カナダから合衆国北部にかけて厚い氷床に覆われていた。人や動物の移動は困難だった。
最終氷河期末期、すなわち一万二千年前、地球の気候が温暖化した頃、西のコルディレラ氷床と東のローレンタイド氷床の間に「無氷回廊」が開通した。その後にアラスカから内陸を経由して北米中央部への移動が可能になったと推定されている。
ただしユーラシア大陸から北米への人類の移動は、内陸ルートよりもまず第一に、太平洋沿岸を海岸伝いになされたと考えるのが自然だろう。
松本は、日本海域から南北アメリカ大陸へ移住拡散して行った可能性は、決して単なる空想の産物ではないと述べている。「ユーラシアの太平洋沿岸言語圏が北米のやはり太平洋沿岸部と最も強いつながりを示していることは、この地域(日本海域:筆者補足)から北米への移住が海岸沿いになされたと想定することによって最もよく説明できる」と。
北米における言語分布を見る時、西部と中部・東部の間の違いが観察される。それは西部が海岸沿いルートを通って移住拡散した人々、中部・東部が遅れて内陸の無氷回廊を利用して拡散した別の集団によって構成されている結果だろう。
松本は次のように述べる。これまで我々は「日本語のルーツ」を求めて、ユーラシア大陸をひたすら見つめていた。しかし、日本語の歴史は今まで考えられてきたよりもはるかに古く、日本列島自身の中に内包されていたのだ。
新人と呼ばれる現代型の人類が、日本列島とその周辺に到来した後期旧石器時代まで遡ることになる。その後さらに、一万年に及ぶ縄文時代を通して、日本海地域で話されてきた「環日本海諸語」が、日本語の母体となったと考えるべきだろう。
日本列島は、ユーラシア大陸からさまざまな人やモノ、言語が流れ着く「吹き溜まり」ではなかった。後期旧石器時代のある時期、日本列島はアメリカ大陸に移住するための一つの拠点となった可能性がある。
縄文時代、日本列島に住む人々は最も先進的な土器文明を生み出していた。南太平洋地域よりも数千年以上早い時期にである。
日本語と同系統の言語を探すならば、ユーラシア大陸内部ではなく、むしろ東南アジア、またはるか遠くのアメリカ先住民の言語をみるべきである。日本語の母体となった「環日本海言語」は、太平洋を取り囲むそれよりはるかに広大な「環太平洋言語圏」の一部に他ならなかった、と。
もっと言えば、「日本語は孤立言語であるという常識」はここに覆されたのである。インド-ヨーロッパ語族のような近しい仲間は多くない。しかし環太平洋言語圏という大きな集団に属しており、インド-ヨーロッパ語族よりも古く、そして沢山の仲間がいると言えよう。
Ⅳ)新人の東南アジア、東アジア展開と言語分布
ⅰ)後期旧石器時代の言語分布
市井の研究家、伊藤俊幸氏はご自身のブログで日本語の成立を論じている。その中で、後期旧石器時代における、東南アジア、東アジアの言語分布想定図を提唱している。
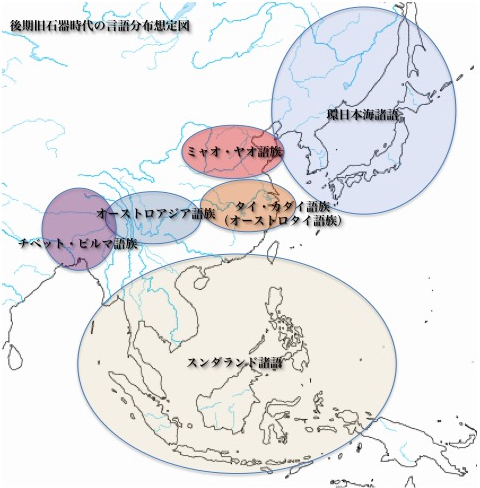
後期旧石器時代における言語分布想定図
松本克己氏が想定した後期旧石器時代の言語分布
ユーラシア太平洋沿岸言語圏、南方系および北方系
(http://www.geocities.jp/ikoh12/honnronn5/005_03_2nihonngo_no_kigenn-kyuusekkijidai.html の伊藤俊幸氏による図を改変)
当時、東南アジアにはスンダランドが拡がっていた。そこにスンダランド諸語を話す人々が存在した(薄い茶色)。環日本海諸語は、日本列島、琉球列島、朝鮮半島、アムール川流域などに住む人々によって話されていた(薄い水色)。
チベット・ビルマ語族(紫色)、オーストロアジア語族(少し濃い水色)、タイ・カダイ(オーストロタイ)語族(オレンジ色)、ミャオ・ヤオ語族(薄い赤色)は、図のそれぞれの地域に分布していた。
ⅱ)現代の言語分布
現代におけるユーラシア大陸太平洋沿岸言語圏の言語分布は、次の図のように調べられている。太平洋沿岸言語圏の北方群は日本語、朝鮮語、漢語、チベット語であり(図上)、南方群は下図の左から、オーストロアジア語族、オーストロタイ語族、ミャオ・ヤオ語族それぞれの分布である。
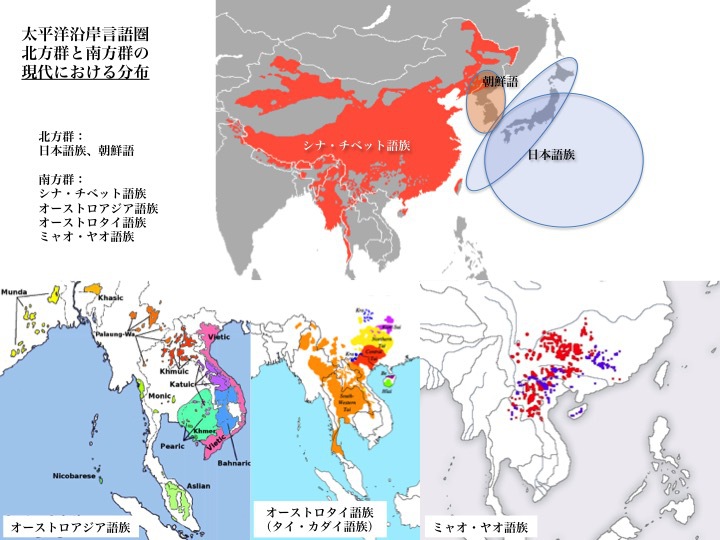
現代におけるユーラシア太平洋沿岸言語圏の語族分布(南方群と北方群)
それぞれWikipediaによる(CC BY-SA 3.0、一部改変)
上図:シナ・チベット語族、日本語族、朝鮮語
下左図:オーストロアジア語族
下中図:オーストロタイ語族の分布
下右図:ミャオ・ヤオ語族、
それぞれ現代における分布図
より大きな図はこちら
漢語を話す人々が爆発的に増加し、オーストロアジア系、オーストロタイ系、ミャオ・ヤオ系の人々は南方か、山岳地帯に追いやられた。そう考えられている。
ⅲ)ハプログループO集団と言語系統樹
ベルン大学の George van Driem(ジョージ・ファン-ドリエム)はアジアの言語系統をYdnaハプログループの系統樹と組合わせて示した。
古い祖先が共有していたと思われる祖言語を Proto-Asiatic(プロトアジア型)と呼び、そこからSouthern-Asiatic(Austric:オーストリック、南アジア型)、Northern-Asiatic(北アジア型)という言語集団に分かれたとしている。
前者すなわち、南アジア型から Austro-Tai(オーストロタイ)語族と Austro-asiatic(オーストロアジア)語族が生まれた。Austro-Tai(オーストロタイ)語族を親として Austronesian(オーストロネシア系諸語)が出て、その後に台湾の Formosan(フォルモサ)諸語、Malay-Polynesian(マレー・ボリネシア)系統に続いている。
同じ Austro-Tai(オーストロタイ)を元にして Tai-Kadai(タイ・カダイ)が生まれ、そこから Kam-Tai(オーストロタイ)も分かれ、Kadai(カダイ)、Kam-Sui(カム-スイ)、Tai(タイ)の各言語につながっているとした。
以上がO1aハプログループに属する集団である。Austro-Tai(オーストロタイ)はタイ語、華南少数民族の一部などの言語となっている。
同じく Austric(オーストリック)から Austro-Asiatic(オーストロアジア)が生まれ、Munda(ムンダ)、Mon-Khmer(モン・クメール)語という言語集団となったという。これらはハプログループO2a1に属する。
Munda(ムンダ)はインド東部からバングラデシュの民族で、Mon-Khmer(モン-クメール)はベトナム語、クメール語、モン語などインドシナ半島の言語である。
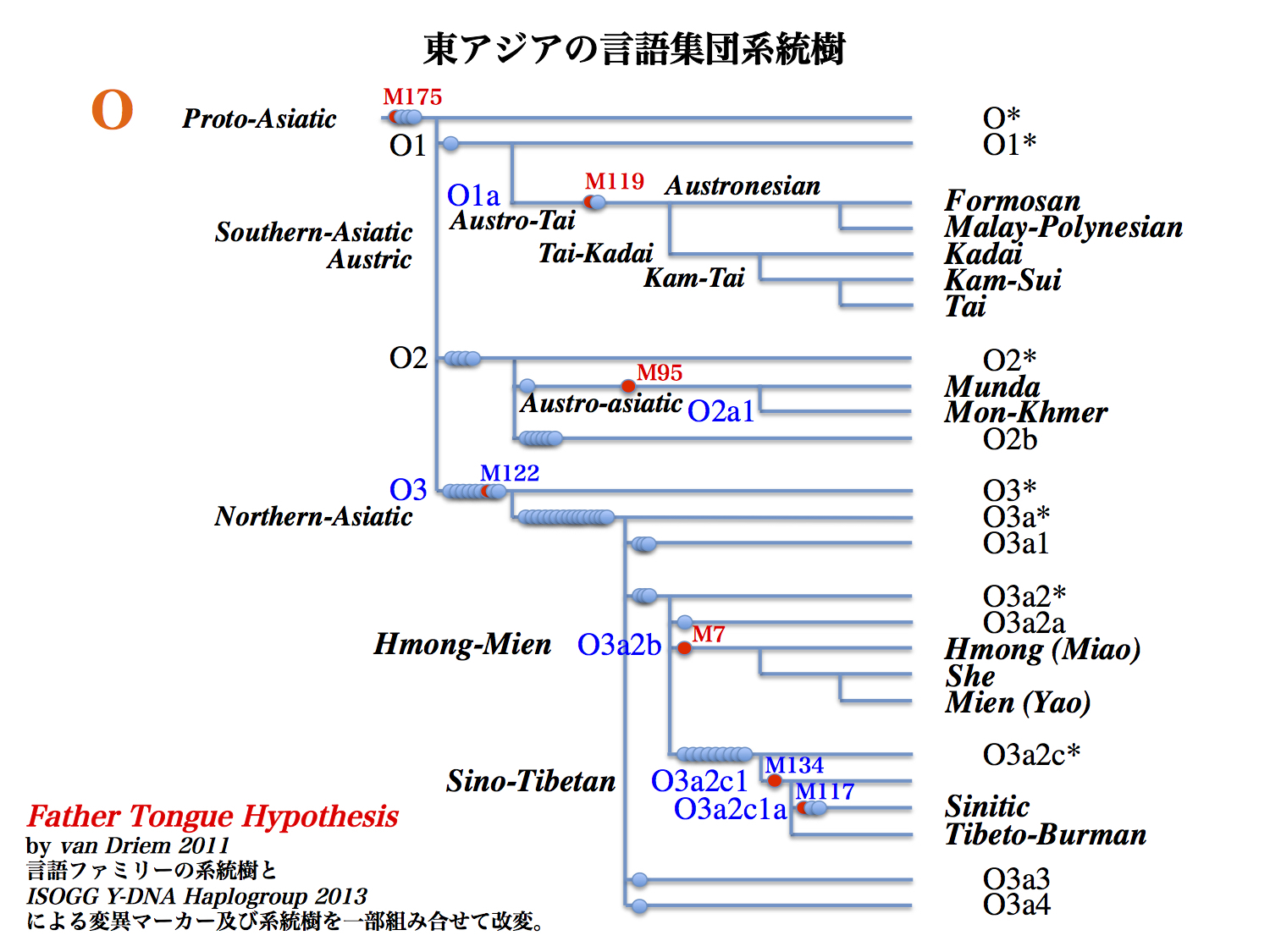
東アジアの言語集団系統樹
国際遺伝系図学会(ISOGG 2013)によるハプログループOの系統樹に、東南アジア言語集団の特徴を重ねて示した図。Father Tongue Hypothesisと称されている。
van Driem "Rice and the Austroasiatic and Hmong-Mien Homelands" in N.J.Enfield ed. "Dynamics of Human Diversity" 361-390, 2011 より改変。
より大きな図はこちら
後者の Northern-Asiatic(北アジア型)から Hmong-Mien(モン-ミェン)、Sino-Tibetan(シナ-チベット)諸語が分かれた。これらはハプログループO3に属する。
Hmong-Mien(モン・ミェン)は華南からインドシナ北部山岳地方の少数民族の言語で、ミャオ-ヤオ語族とされている。モン-ミェン語族はO3a2bが特徴的である。
Sino-Tibetan(シナ-チベット)諸語はシナ語、チベット語、ビルマ語を含むグループである。シナ語族はO3a2c1およびO3a2c1a、チベット語族とビルマ語族はO3a2c1bがそれぞれ特徴的である。
男性を決定づけるY染色体DNAハプログループによって分けるため、母語(mother tongue)をもじって「Father Tongue」仮説(Father Tongue Hypothesis)と名付けられた。たいへん洒落ている。
ここまで単純に分けられるものかどうか、素人目には不思議に思える。しかし、環日本海諸語に含まれる日本語、朝鮮語を話す人々に特徴的なのがO2b、O2b1であることをあわせて考えると、ある程度の全体像を言い当てているように思える。
ここで注目すべきことのもう一つは、O2b/O2b1は北方系(Northern-Asiatic)ではなく、南方系(Southern-Asiatic)とくにオーストロアジア系(Austro-Asiatic)に近い関係にあるという事実だ。日本語のルーツは大陸内部ではない。東南アジアだと言って良いだろう。
日本人と日本語は東南アジア(スンダランド)に深いつながりがある。Ydna研究の結果ばかりでなく、言語類型地理論なども、両者の関係を示唆している。
Ⅴ)日本語の成立過程
前述の伊藤俊幸氏は、日本語の成立過程について次のような仮説を展開している。
まず後期旧石器時代、日本列島が大陸と繋がり、朝鮮半島とも大きな川のような隔たりしかなかった頃、環日本海諸語が存在した(次の図参照)。
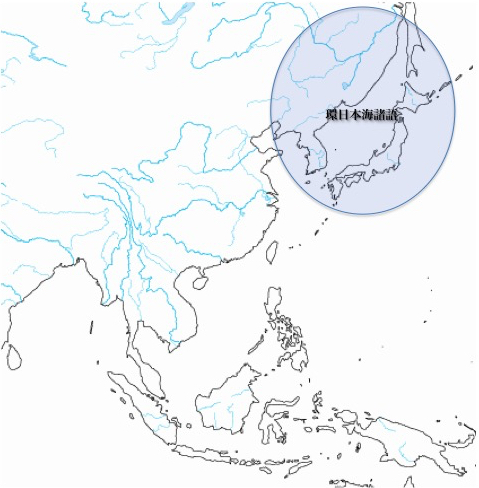
環日本海諸語の存在
海面レベル上昇によって日本列島が大陸と分離した後、日本基語、朝鮮祖語、古アイヌ語に独立していった。日本基語のうち、九州北部の言葉が倭人語(日本祖語)として形づくられた(次図参照)。
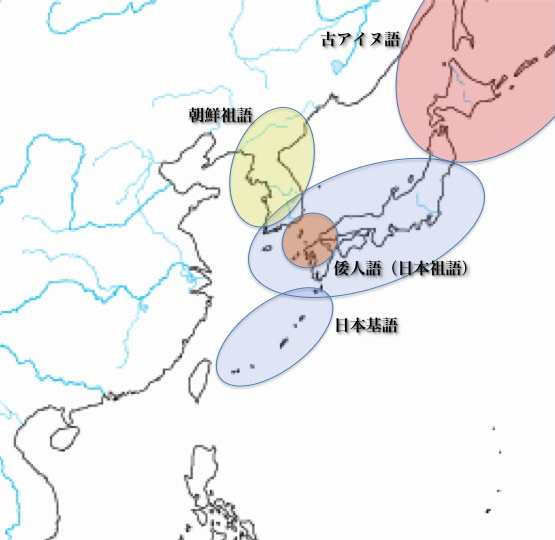
日本基語、朝鮮祖語、古アイヌ語の分布と倭人語(日本祖語)の登場
時代が下って、大和朝廷の支配が日本列島の大部分に及ぶ。奈良時代の八世紀頃、上代日本語が成立した。南方には琉球語、北方にはアイヌ語、朝鮮半島には朝鮮語が独自の発展を遂げた(次図参照)。
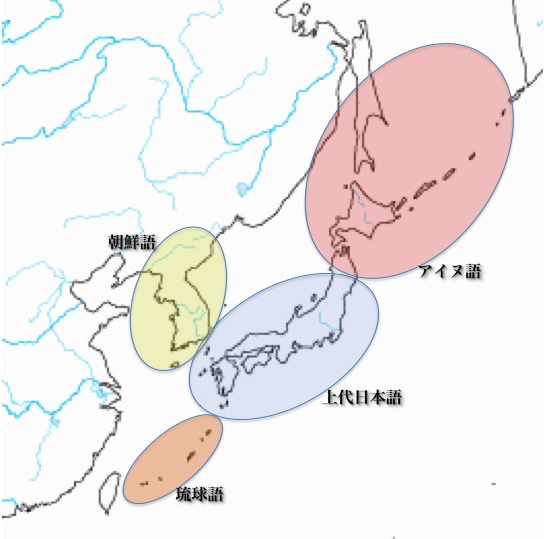
上代日本語(奈良時代の日本語)の成立と琉球語、アイヌ語、朝鮮語
以上は、説得力ある説ではないかと感じられる。先史時代に環日本海諸語が存在した。これは受け入れるのに何の問題もないだろう。それが日本語、琉球語、アイヌ語、朝鮮語となっていったというのも、魅力ある仮説だ。
ただし、日本語、琉球語、朝鮮語それぞれの間の距離より、アイヌ語とその他の環日本海諸語の間の距離の方が遠いことは確かだ。
その後時代が下ると遺跡や遺物が増え、さらに下ると歴史時代に突入する。遺跡、遺物が日本語のルーツを物語ることは少ないかもしれないが、それでも有力な説の傍証とはなるだろう。歴史時代の史料などを加味して学際的に展開するとどうなるか。最後の項で少しふれてみたい。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
このページのまとめ
1)日本語が孤立言語であるという常識は覆された。
2)環太平洋言語圏という大きな集団に属している。
3)インド-ヨーロッパ語族よりも古く、たくさんの仲間がいる。
4)ユーラシア大陸の中では太平洋沿岸言語圏の北方群、環日本海諸語に属する。
5)Y染色体ハプログループ研究とあわせて、日本語は北方系ではなく南方系とくにオーストロアジア系に近い。
6)日本語のルーツはアジア大陸内部ではない。東南アジアだと言ってよい。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
日本人のルーツ(X)日本人は南から来た
2014.10.23
日本人は南から来た 
縄文時代の火炎土器
日本人は南から来た
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
このページのまとめ
1)日本人の祖先は後期旧石器時代にスンダランド(東南アジア)から来た。
2)Y染色体ハプログループ、常染色体マーカー、日本語のルーツの研究が1)を支持。
3)「二重構造説」は完全に破綻した。
4)弥生人が縄文人に置き換わって多数派になったというのはウソだった。
5)縄文人と北東アジア系の混血という説も間違っていた。
6)後期旧石器時代の日本海を囲む地域で、日本語の原型はすでに整っていた。
7)一万年もの長い縄文時代の中で日本列島で培われ、日本語はさらに成熟した。
8)強力な外敵の侵入を受けず、苛烈な殺し合いが延々と演じられることもなく、
9)男も女も多様性を持った集団(ハプログループ)として存続することができた。
10)奇跡の場所!それが日本列島だ。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
ここまで「日本人は南から来た」ことを論じてきた。簡単にまとめてみよう。
日本人の祖先が日本列島に到来した経路は、スペンサー・ウェルズや他の研究者が主張していたようなもの(次図のAとB)ではないだろう。
むしろ海岸沿いルートをたどり、南アジアを経由して東南アジアに行き、そこから海岸沿いルートで北上して日本列島にたどり着いたと考えるのが有力だ(次図のD)。常染色体SNP(一塩基多型)の大規模データ解析も南→北ルートを示唆している(次図のC)。
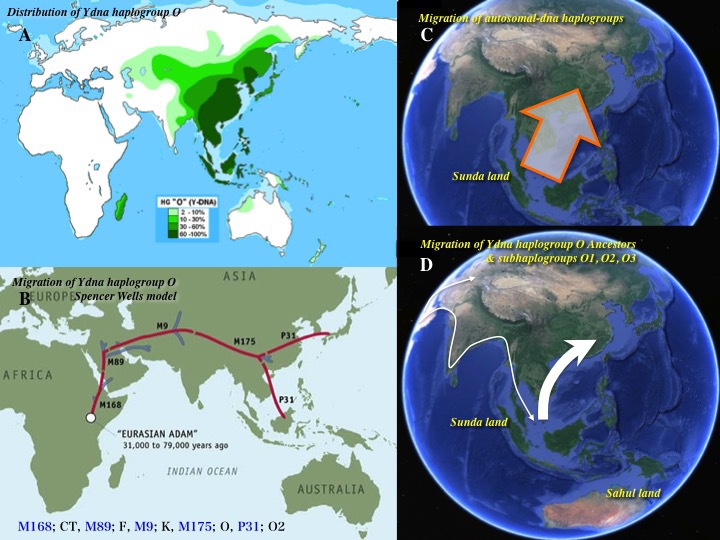
スペンサー・ウェルズのモデルか
沿岸ルートモデル(東南アジアから東アジア<南→北>方向の移動)か?
YdnaハプログループOの場合
(A)YdnaハプログループOの分布(左上図)
Wikipediaによる(CC BY-SA 3.0)
(B)かつて考えられていたYdnaハプログループOの移動経路(左下図)「National Geographic Society の Genographic Project」による
(C)常染色体SNP(Single Nucleotide Polymorphism:一塩基多型)の大規模データ解析から得られた南→北ルートの可能性(右上図)
(D)YdnaハプログループOの海岸線沿い移動モデル(右下図)
より大きな図はこちら
後期旧石器時代、地球は氷河期だった。新人の子孫たちは南方の暖かい海岸沿いルートをたどり、過酷な自然条件の中、わずかでも有利な地を探し当てようとしただろう。わざわざ、さらにさらに過酷なユーラシア中央高原ルートを多数派集団が選ぶだろうか。
マンモスハンターなどの集団は確かに存在したが、それは環日本海地域を経由してユーラシア大陸に入ったグループであっても不思議はない。環日本海地域の中の北部の集団もそれに含まれるだろう。ただしグループは少数派集団だったと考えられる。
日本語のルーツからも「日本人は南からきた」と言える。松本克己が言うように、日本語は大きな「環太平洋言語圏」の一部を構成し、特に「ユーラシア大陸太平洋沿岸部言語圏」に入ると考えられるからだ。
言語類型という特徴で見ると、日本語は多くの類型においてユーラシア大陸内陸部の諸言語とは似ていない。語順SOVと名詞の格標示「対格型」は似ているが。それよりも、ユーラシア大陸沿岸部の諸言語に類似している。
また崎山 理が言うように、上代日本語の語彙はオーストロネシア系のそれと似ている点も注目すべきである。オーストロネシア諸語は、まさしくユーラシア大陸沿岸部南方系言語圏に属している。
ただし環日本海諸語としての原日本語の成立時期については、崎山よりも松本の説を取りたい。すなわち一万年以上も前の後期旧石器時代である。縄文時代とそれ以降は、既にオーストロネシア諸語の影響を受けた後に過ぎない。
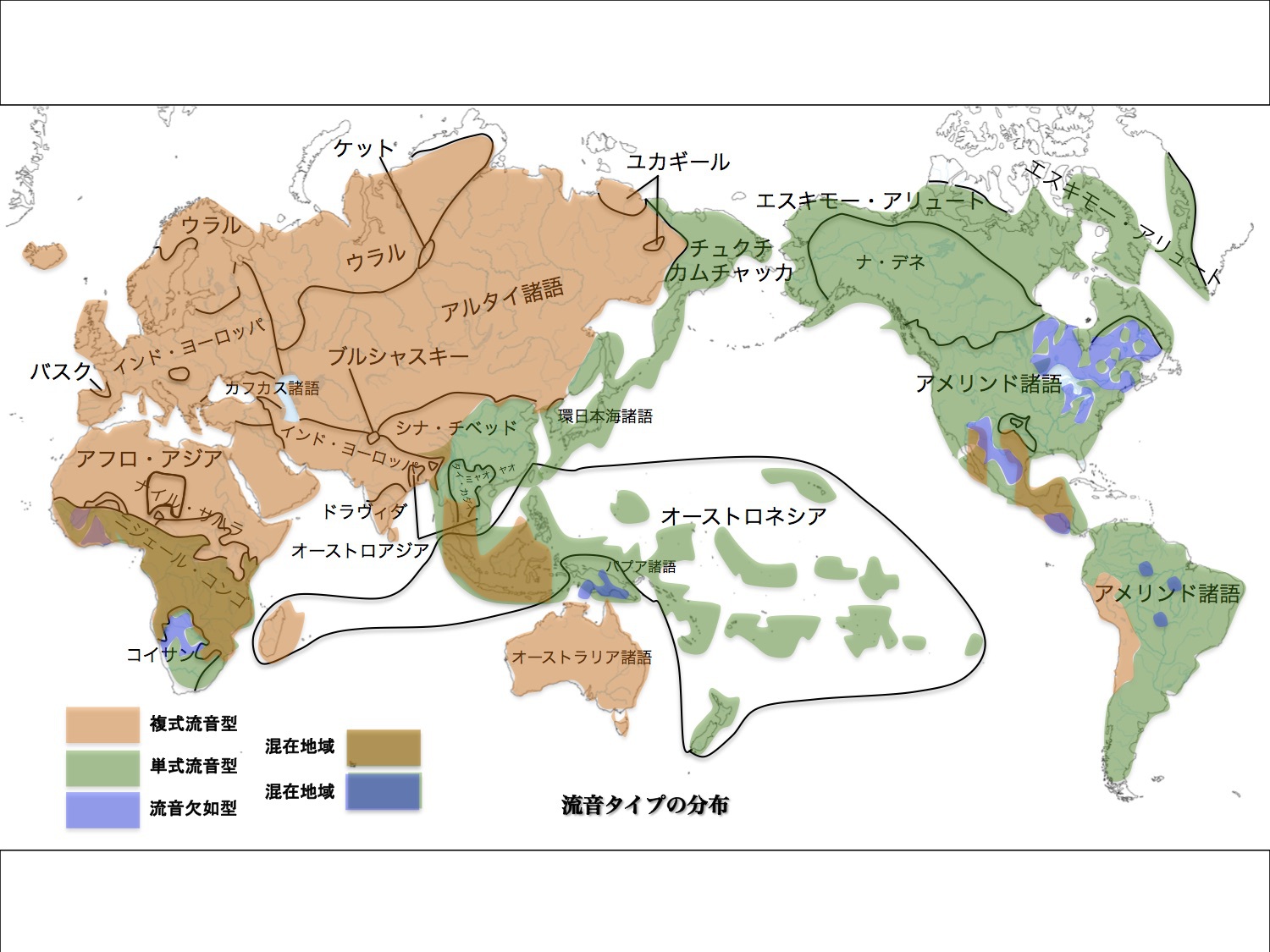
単式流音タイプの言語分布
日本語はユーラシア大陸内陸部の言語群の仲間というより
ユーラシア大陸太平洋沿岸部諸言語に近い特徴を有する
より大きな図はこちら
日本語は、単式流音タイプであるという点にとどまらず、太平洋沿岸部諸言語に特徴的で共通した性質を備えている。繰り返しになるが、一万年以上も前、後期旧石器時代には日本語の原型がすでにできあがっていたと考えるのが妥当だ。
長江文明の担い手が日本に渡来して弥生人となった。弥生人が縄文人に置き換わって多数派になった。縄文人は少数派となった。そういった「二重構造説」はすでに破綻している。
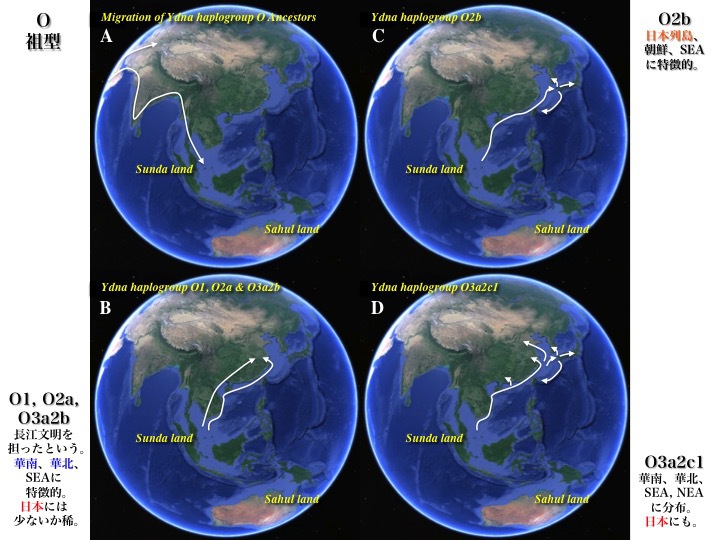
Ydnaサブハプログループ O1/O2a/O2b/O3a2b/O3a2c1 の推定移動経路
(A)YdnaハプログループO祖型の海岸ルート移動とスンダランドへの定着
(B)東南アジアあるいは華南(および華北)に特徴的で、日本には少ないかほとんど稀なサブハプログループO1、O2a、O3a2bの移動。長江文明の担い手とされている
(C)日本周辺に特徴的で、東南アジアにも一部認められるサブハプログループO2b、O2b1aの移動
(D)東南アジア、華南、華北、北東アジアに存在するO3a2c1の移動
より大きな図はこちら
華南の長江文明集団を形づくっていたのは、YdnaハプログループO3a2b(モン-ミェン族)、O1a/O2a1とされている。しかしそれらは、O1aがたかだか3.4%であり、日本にほとんどわずかしか、あるいはまったく存在しない。すなわち二重構造説は成り立たない。
シナ大陸に特徴的なO3a1c系統は日本にほとんどいない。同様にO3a2c1/O3a2c1aもシナ大陸に特徴的だが、日本では数%を数えるにとどまっている。逆に数%もいると言うべきだろうか。O3a1c、O1a/O2a1がほとんどいないことを二重構造説は全く説明できない。
いずれにせよ、シナ大陸の集団が日本に来て多数派を占めるに至ったと考えるのは、理論的に無理である。朝鮮半島の集団も同様だ。後述するように、朝鮮半島のYdnaハプログループ構成は、日本列島、華北、モンゴルからの流入を想定しないかぎり説明できない。
もう一度確認しよう。もう「二重構造説」を信じてはいけない。
Ydnaハプログループで日本に多く見られるC/D/Oは、どのような経路を通って日本列島に到達したのだろう。
図に示すように、C/D/Oすべてが海岸沿いルートを経てスンダランドに到達(図A)。それから北方に転じて、日本列島に展開したと考えるのが最も有力である。
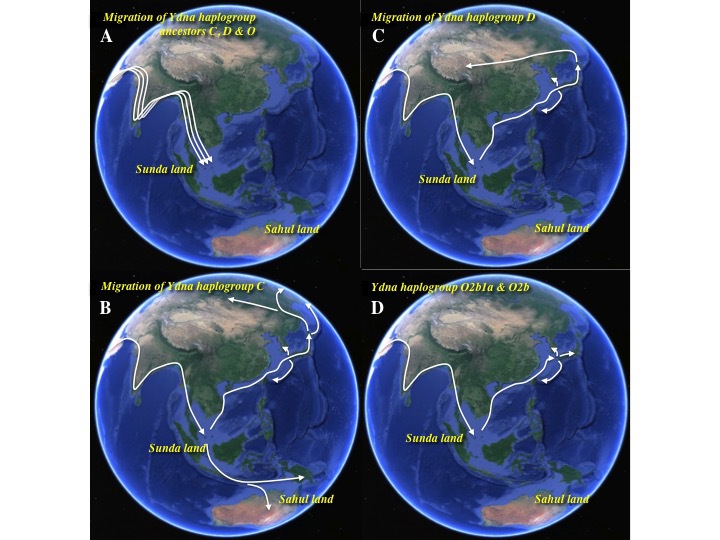
YdnaハプログループC/D/Oはすべて南から日本に到達した
(A)YdnaハプログループC、D、O祖型の海岸沿いルート移動とスンダランドへの定着
(B)ハプログループCの全世界への移動と展開
(C)ハプログループDの日本附近への移動とチベット方面への展開
(D)日本周辺に特徴的で、東南アジアにも一部認められるサブハプログループO2b、O2b1aの移動
より大きな図はこちら
ハプログループCは、スンダランドから北上して日本列島に到達。そこからユーラシア大陸に戻り、大陸内部と北米大陸を目指す集団に分かれた(図B)。もちろん図には示さなかったが、日本列島を経由せずにユーラシア大陸内陸と北米大陸を目指したのかもしれない。
亜型C3がシベリア、北東アジア、中央アジア、北米に拡がっている一方、日本にも痕跡を残している。
日本人の3.1%がC3であり、2.3%がC1である。そしてC1が日本にだけ存在する亜型である。これらの事実が、C3が日本経由でユーラシア大陸内陸部と北米に拡散したと考える根拠である。
他方、亜型C*、C5はインドにとどまり、C5の一部とC2はニューギニアに向かい、C4はオーストラリア大陸に行き、C*の一部とC6はオセアニアに達した。ハプログループCの各亜型の分布はたいへん興味深い。
Dは日本とチベットに多い。本稿では次のように想定した。D集団はスンダランドを経て北上し、日本にたどり着いた(図C)。地続きだった間宮海峡を通ってユーラシア大陸に渡り、内陸を旅してチベットに至った。途中にも留まったが、後続集団に駆逐または絶滅させられた。
O2b、O2b1aの移動は簡単である。スンダランドを経て環日本海地域にたどり着いた(図D)。ごくごく一部がインドネシア西部やベトナムに留まったり、ミクロネシアに行ったりした。
以上を元に、Y染色体DNAハプログループから見た、新人の日本およびユーラシア大陸への拡散をおさらいする(次図)。
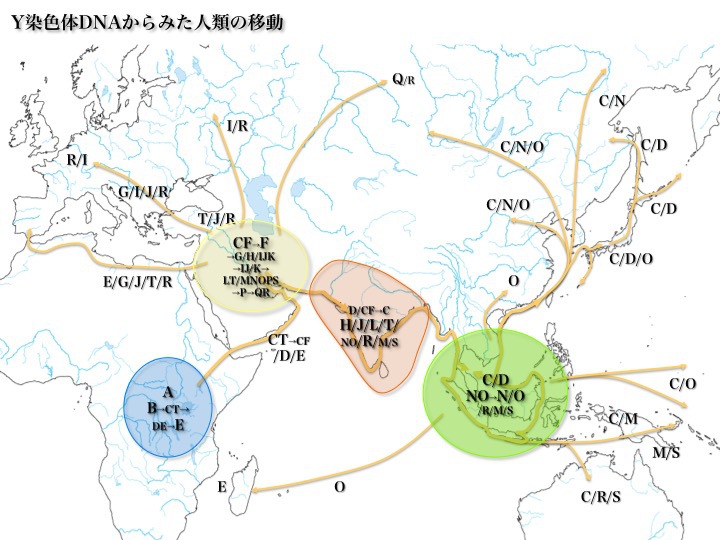
Y染色体DNAハプログループから見た
アダムの息子たちの日本とユーラシア大陸への拡散
より大きな図はこちら
アフリカ東部地溝帯で誕生した新人は、バブ-エル-マンデブ海峡を渡って出アフリカを果たす。アラビア半島を海岸沿いに半時計回りにたどってペルシャ湾に到達する。当時のペルシャ湾はホルムズ海峡が地続きで内海化しており、豊かな渓谷だった。
ペルシャ湾渓谷で増えた新人のうちに、西、北、東をそれぞれ目指す集団が出現する。
西に向かったのは主にハプログループG/I/J/T/Rだった。Eはアフリカに再侵入することになる。残りはペルシャ湾で先祖から分かれた子孫である。後にヨーロッパ人の先祖となったのが主にR/Iの集団だ。R/Iはカフカス(コーカサス)山脈を越えるなどして北にも向かっただろう。
北に向かった集団のうちカスピ海東部を通ったのがQ/Rである。Q/Rはユーラシア大陸中央高原にとどまった集団の他、当時陸続きだったベーリング海峡を通ってアメリカ大陸に入り著しく拡散した。
他方、東に向かった集団はJ、R、Tそれぞれの一部、C/H/L/NO/M/Sである。そのうちH/J/L/T集団はインダス川沿いの渓谷をはじめインドに住み着いた。C/D/N/O/R/M/Sはスンダランドにたどり着く。
C/R/Sはオーストラリアに、C/M/Sはニューギニアに、C/Oはポリネシアに向かった。Oの一部はインド洋を航海し、マダガスカルにたどり着いたと考えられる。他方、C/D/N/Oは北上し、日本列島周辺やシナ大陸、ユーラシア大陸内陸部、一部は北米大陸へと向かった。
以上がアダムの子孫たちの主な移動経路である。
ミトコンドリアDNAのハプログループも同様にまとめる(次図)。
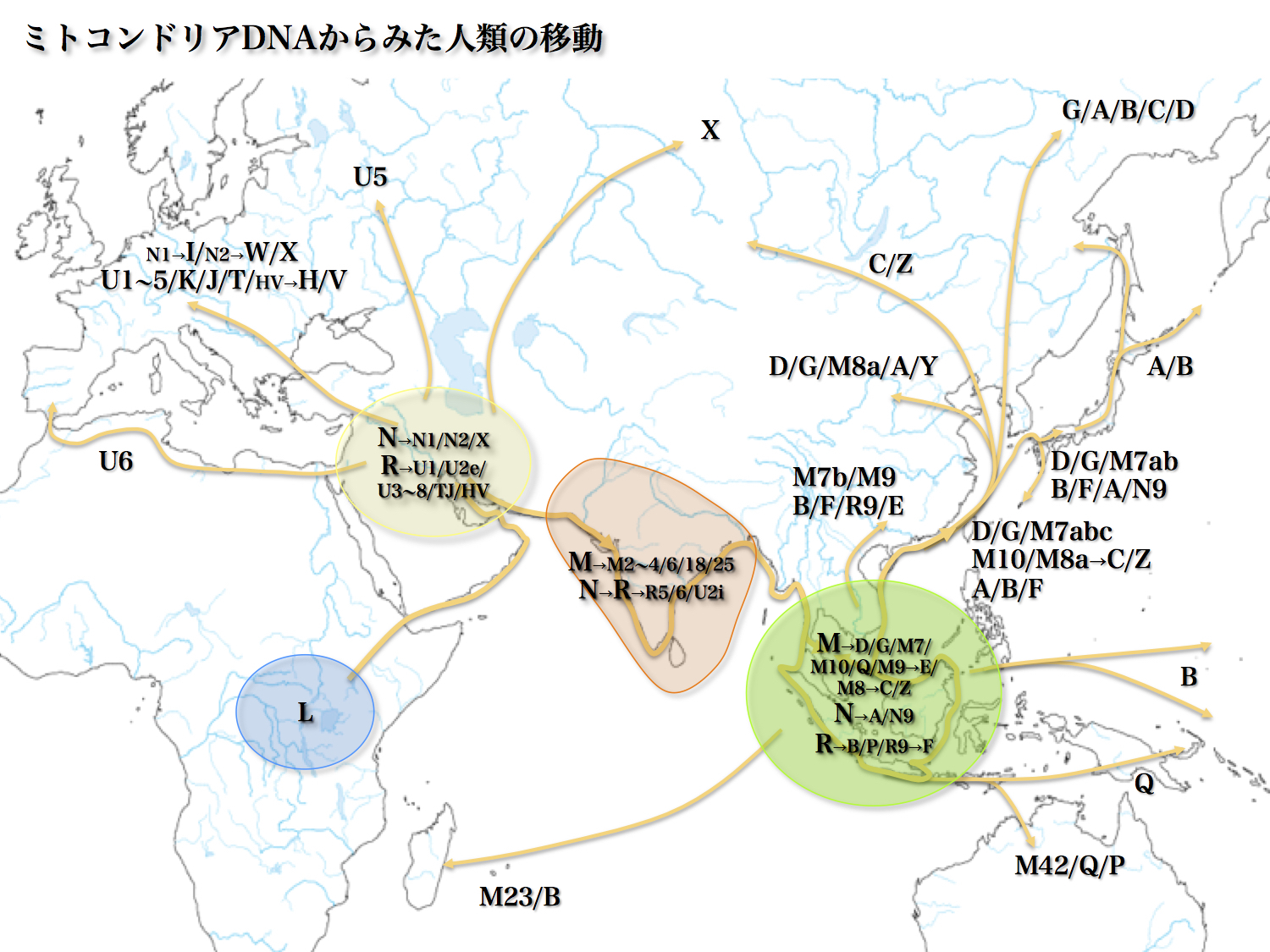
ミトコンドリアDNAハプログループから見た
イブの娘たちの日本とユーラシア大陸への拡散
より大きな図はこちら
ハプログループM/Nが出アフリカを果たす。豊かなペルシャ湾渓谷にたどり着きそこに定住して増えてゆく。Y染色体で見たと同じように、西と北、東に向かう集団が出現する。
地中海南岸沿いに西へ向かった主な集団が、ハプログループNの子孫Rの系統であるU6だ。ヨーロッパに入ったのが、Nの子孫I/W/X、Rの子孫U1~5/K/J/T/H/Vである。ユーラシア大陸中央高原を経由して北米大陸に向かったのがXではないかと考えられる。
他方、東に向かってインダス川渓谷にたどり着いたのが、Mの子孫M2~4/6/18/25、Rを祖先とするR5/6/U21である。Mの子孫D/G/M7/10/Q/E/C/Z、Nの子孫A/N9、Rの子孫B/P/Fがスンダランドに到達する。
そこからオーストラリアにMの子孫M42/QとRの子孫P、ニューギニアにMの子孫Q、ポリネシアにRの子孫B、マダガスカルにMの子孫M23とRの子孫Bが向かう。
他方、北を目指したのがMの子孫D/G/M7abc/M9/M10/C/Z、Nの子孫A、Rの子孫B/F/R9である。華南にとどまったのがM7b/M9/B/F/R9、残りが日本列島、華北、ユーラシア大陸内陸部、北米大陸を目指した。
日本列島にはMの子孫D/G/M7ab、Nの子孫A/N9、Rの子孫B/Fがたどり着いた。華北にはD/G/M8a/A/Y(Nの子孫)、ユーラシア大陸内陸部へはC/Z、北米大陸にはD/G/C/A/Bが渡って行った。
以上がイブの子孫の主な拡散経路である。
こうして見てきたように「日本人が南から来た」という説は、決して荒唐無稽でも何でもなく、全体として説得力のある「マクロな考え方」と言えるだろう。
日本人はどこから来たか?単一起源説が正しいと受け入れられているいま、次のように考えるのが妥当だ。
アフリカ→ペルシャ湾渓谷→インダス川渓谷→スンダランド→北上して環日本海地域にたどり着いた。しかも後期旧石器時代に。日本語の祖先もその頃には原型が整っていた。
一万年もの長い縄文時代の中で日本列島で培われて、日本語がさらに成熟し、まとまって行った。以降、強力な外敵の侵入を受けることも、苛烈な殺し合いが延々と演じられることもなく、男も女も多様性を持った集団(ハプログループ)として存続し得た奇跡の場所。
それが日本列島だ。当然の結論である。この幸いを味わい、静かに喜んでも良いのではないかと確信する。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
このページのまとめ
1)日本人は後期旧石器時代にスンダランド(東南アジア)から来た。
2)Y染色体ハプログループの研究、常染色体マーカーの研究、日本語のルーツの研究のどれもが1)を支持している。
3)「二重構造説」は完全に破綻した。長江文明の担い手が稲作を携えて日本に渡来して弥生人となり、弥生人が縄文人に置き換わって多数派になったというのはウソだった。
4)後期旧石器時代の日本海を囲む地域で、日本語の原型はすでに整っていた。
5)一万年もの長い縄文時代の中で日本列島で培われ、日本語はさらに成熟した。
6)強力な外敵の侵入を受けることなく、苛烈な殺し合いが延々と演じられることもなく、男も女も多様性を持った集団(ハプログループ)として存続することができた。
7)奇跡の場所!それが日本列島だ。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
<追補>
日本語と朝鮮語のルーツについて
二〇一四年一月、長浜浩明氏が「韓国人は何処から来たか」という本を上梓した。韓国人のルーツ、韓国語の成り立ちを冷徹に見つめる、これまでなかったユニークな仮説と思われた。
本ブログ「Bookshelf」で既に紹介したが、「日本人のルーツ」を考察する本稿でも重要かつ有益と判断した。ここに取り上げることにする。
朝鮮人は何処から来たか。正面から論じた本はない。論ずるまでもない。彼らは日本の誕生はるか前からいた。進んだ文化を持ち、日本の兄貴分だった。シナの文化は彼らの手を経て日本にやってきた。そう信じられて来た。
だが科学的、論理的に検証することによって、著者は定説の誤偽を明かにしようとした。
まず遺跡の数と種類、古代人の骨格などから検討を加える。旧石器時代、半島はほぼ無人だった。遺跡は五〇ヶ所程度しかない。日本の遺跡数は三千~五千ヶ所。単位面積あたりの遺跡数は、日本の百分の一以下。
更にBC一万年~五千年、ヒトの気配が半島から完全に消える。新石器時代人の流入はBC五千年頃。旧石器時代から連綿と今日に至る日本人とは大違いだ。無人の半島に日本から縄文人が渡った。縄文遺跡が現れ、その人骨の特徴は縄文人そのもの。現在の韓国人に似ていない。
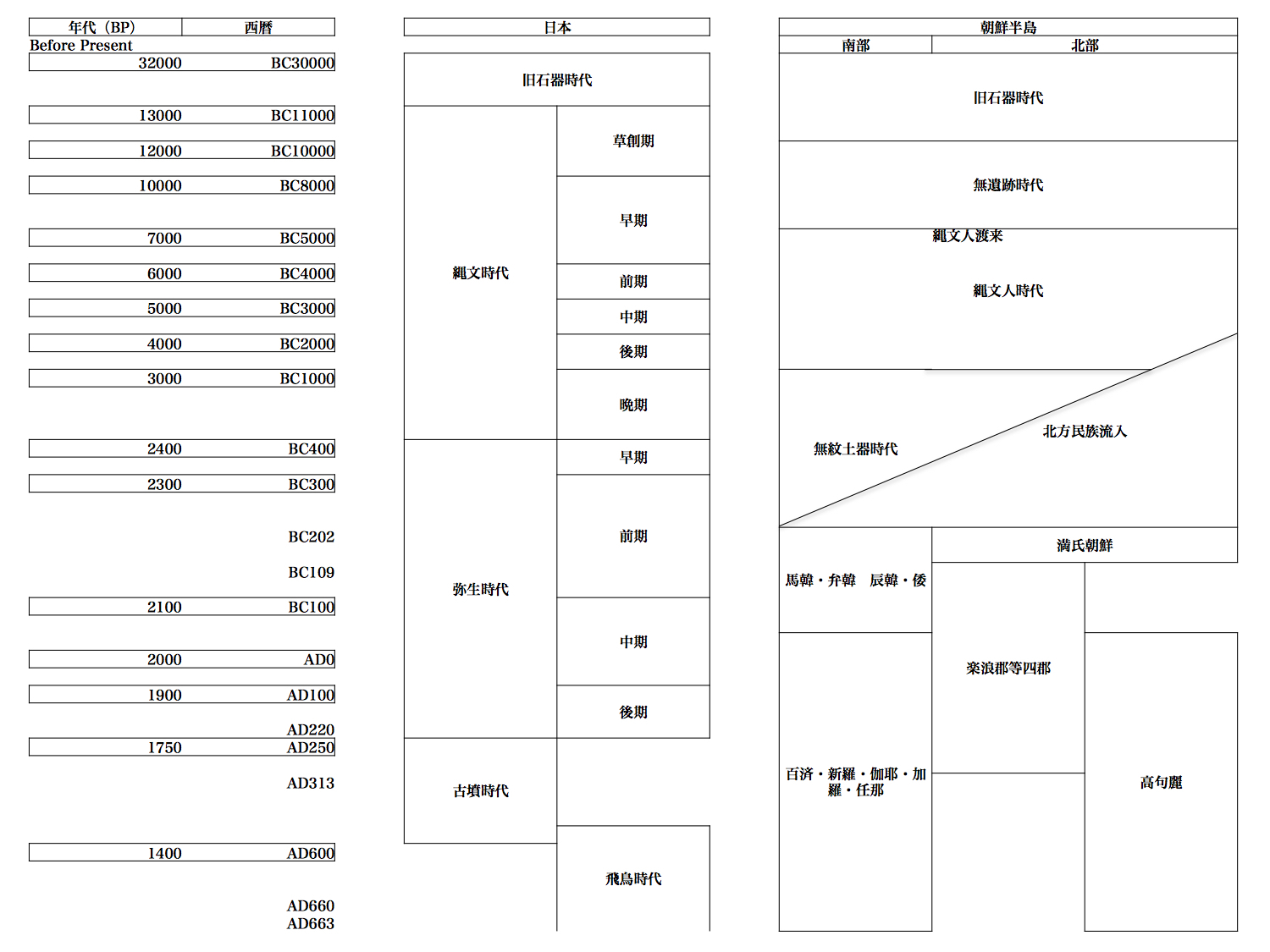
日本と朝鮮半島の歴史年表(考古学時代~古代まで)
より大きな図はこちら
Y染色体DNAハプログループの研究から、朝鮮半島の人々は日本人、シナ人、モンゴル人の特質を有していることが判明している。日本人に特徴的なO2b1/O2b1aが19%、シナ人に特徴的なO3a2c1が20%、モンゴル人に多いC3、Kがそれぞれ13%と8%とされている。
(データはO3a2c1がHammer, 2006、それ以外がJin, 2003による)
女性のミトコンドリアDNAハプログループの研究からは、日本と朝鮮半島、シナ大陸東北部(旧満州)で、その分布頻度がほとんど同じであることが判明している。
日本と朝鮮半島で女性の遺伝子が変わらず、男性だけ大きく違っているのは何故か?それは元々同じ遺伝子をもった人々が住みついていたところに、朝鮮半島では圧倒的な外敵が押し寄せ征服されてしまったからだ。
日本、北方シナ、蒙古から半島への人の流れを想定せずに、上記の事実は説明できない。具体的には次の通りである。
先史時代、日本と朝鮮半島には同一の集団が暮らしていた。しかしBC二千年頃、縄文人の住んでいた半島に、北方シナ人が流入し始める。
歴史時代に入る。三国時代の新羅、百済は日本の臣民だった。新羅が裏切りシナ軍を招き入れる。三国時代の後、蒙古人、満洲人が侵入する。置換に等しい混血を経て現代の韓国人となった。
日韓の言葉は八世紀末まで通じていた。韓国の公式見解であるという。三国史記や日本書紀における、双方の登場人物が通訳なしで会話できた例を挙げる。
なぜ通じなくなったか?北からの侵略を受け、意図的に語彙を置換していったからだ。現在も日本統治時代の言葉が日常の生活からどんどん駆逐されている。ただ言葉の基本は縄文語や上代日本語。基本構造は変えられない。似ているが通じない!となったわけだ。
九世紀頃から日韓の言葉が通じなくなり、十五世紀にハングル文字が作られる。朝鮮半島の人々はようやくまともな書き言葉を持ったが、ほとんど使われなかった。激しく蔑まれ迫害されたからだ。人々に広く行き渡るには、日本統治時代を待たなくてはならなかった。
韓国語とは「日本の文法を母とし、シナ人の音を父として出来上がった高々五百年の歴史しかない混合語」であり、韓国人は日本人と北方シナ人の混血だった。これが長浜氏の結論である。
恐らく韓国人の多くは、長浜氏の説や氏の説く現実を受け入れることができないだろう。また日本人の一部も同様に反応するだろう。信じて疑わなかった通説が、根元から揺さぶられるのは心地よいものではない。
特に長浜氏の著述の後半は、彼らにとって耳に痛い記述に満ちている。そして本サイトの筆者からみても、書き過ぎではなかろうかと感じられる部分もある。だが前半の根幹部分は「正論」と言って良いだろう。根拠を明示して反論するのは難しい。
ともあれ、日本語、日本人、日本列島と朝鮮語、朝鮮人、朝鮮半島のつながりが深いレベルで理解できて納得が行く。ハラにストンと落ちるとはこのことだ。
これまで、本書のような切り口で韓国人のルーツに関する「常識」に疑問を呈し、反論する試みに触れたことはなかった。単なる言語学や歴史学、考古学や分子遺伝学ではない。多くを学際的に統合した立場からの仮説ではなかろうか。
「常識を疑う」のは本サイトの大きな主張である。歓迎したい。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
補遺のまとめ
1)朝鮮半島は後期旧石器時代が終わった頃に無人地帯になった。
2)そこに縄文人が移り住んだ(Y染色体ハプログループO2b1、O2b1aあわせて19%)。
3)支那北部からの侵入によりY染色体の置換が起こった(O3a2c1が20%)。
4)モンゴルからの侵入によりY染色体の置換が起こった(C13%、K8%)。
5)朝鮮語の基本構造は日本語と同じ。音は漢語の影響を受け語彙も激しく入れ替わった。
6)朝鮮語は日本語を母とし、漢語を父とする混成言語である。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
 Soliloquy1...
Soliloquy1...